Paper
MixMatch: A Holistic Approach to Semi-Supervised Learning
Semi-supervised learning has proven to be a powerful paradigm for leveraging unlabeled data to mitigate the reliance on large labeled datasets. In this work, we unify the current dominant approaches for semi-supervised learning to produce a new algorithm,
arxiv.org
Code
github.com/google-research/mixmatch
google-research/mixmatch
Contribute to google-research/mixmatch development by creating an account on GitHub.
github.com
Introduction
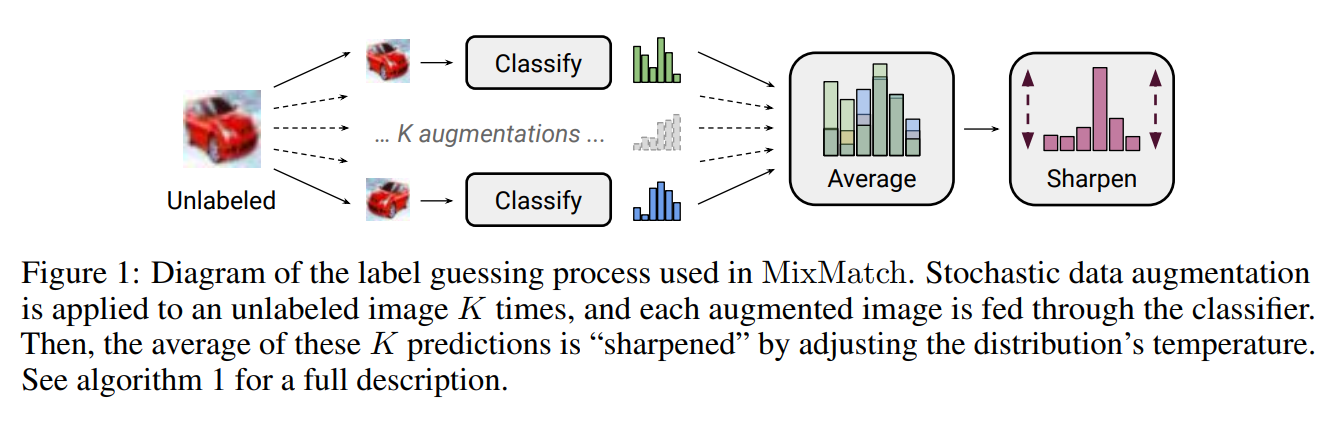
Method

- labelded data x에 대해서 Augmentation을 적용한다.
- unlabeled data x에 대해서 Augmentation을 적용한다.
- unlabeled data x에 대해서 Augmentation을 적용한 결과들을 평균내서 결과를 낸다. -> q_b_bar
- q_b_bar에 대해서 temperature Sharpen을 적용한 결과를 q_b (unlabeled target으로 사용)
- 그리고 Mixup을 통해 학습을 위한 데이터를 재생성한다.
- 먼저 Augmented labeled data X_hat과 Augmented unlabeled data u_hat을 이용하여 W set을 만든다. (concat)
- 형성된 W set을 이용해 MixUp을 사용한다. Mixup을 적용하여 새로운 X' , U'을 만든다. (자세한 건 논문참고)
- 만들어진 X', U'를 이용해서 아래의 loss function을 적용해 학습을 진행한다.
