Pytorch data_loader에서 num_worker를 세팅하는 부분이 있다.
num_worker를 공식문서에서 설명하는 것은 다음과 같다.
num_workers (int, optional) – how many subprocesses to use for data loading.
0 means that the data will be loaded in the main process. (default: 0)
( default 값은 0 이며, 이는 main process만 사용하는 것을 의미한다. 이때, 다른 값을 입력하는 경우 sub process를 추가적으로 얼마나 사용할지를 정하는 것이다.)
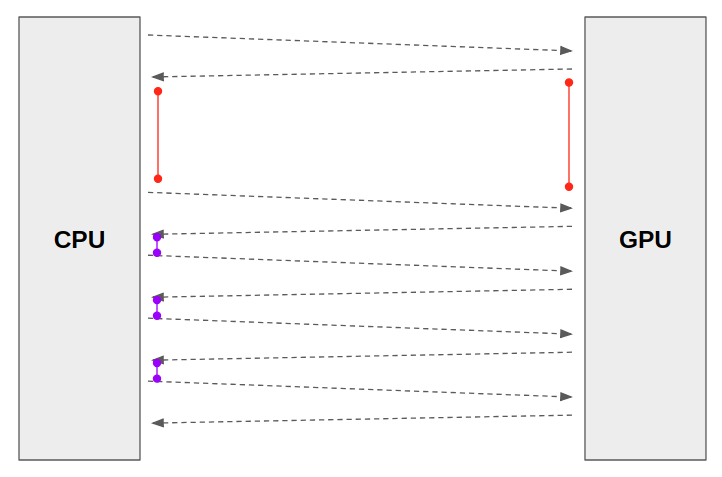
먼저 우리가 GPU를 사용하는 이유는 딥러닝에서 많이 사용되는 행렬 연산을 병렬처리하여 빠르게 연산하기 위함이다.
그러기 위해서는 CPU에 loading되어 있는 data를 GPU로 넘겨주는 작업의 속도도 중요하다. 이때, 넘겨주는 속도가 느리게 되면 전체적인 작업속도가 느려지는 것이고, 이를 빠르게 하기 위해서 멀티프로세싱 방법을 사용할 수 있다.
이에 대한 그림은 아래와 같이 표현된다.
(빨간색은 넘겨주는 속도가 느린경우, 보라색은 이 속도가 최적화되어 빨라진 경우이다.)
가장 좋은 예시는 아래와 같이 GPU 사용률을 100%로 만드는 것이다. ( GPU-Util )

그러면 이러한 의문이 생길 수 있다.
"무조건 많은 CPU코어를 data proceccing에 할당해 주면 좋은거 아닌가?"
이 질문에 대한 대답은
"꼭 그렇지는 않다" 이다.
CPU 코어의 수는 한정되어 있으므로 적당한 수를 지정해주는 것이 좋고,
(CPU 코어는 데이터 로딩 이외에도 다른 일을 해야 되므로..)
코어의 절반 정도를 사용하면 적당하다고 이야기 하고 있다.
자세한 내용은 아래 링크 참고.
https://jybaek.tistory.com/799
DataLoader num_workers에 대한 고찰
Pytorch에서 학습 데이터를 읽어오는 용도로 사용되는 DataLoader는 torch 라이브러리를 import만 하면 쉽게 사용할 수 있어서 흔히 공식처럼 잘 쓰고 있습니다. 다음과 같이 같이 사용할 수 있겠네요. fr
jybaek.tistory.com
'Pytorch' 카테고리의 다른 글
| Pytorch : Variable() 클래스 사용용도 및 의미 (현재는 필요없음) (0) | 2021.09.09 |
|---|---|
| Deep learning model code basic structure (0) | 2021.04.28 |
| THOP: PyTorch-OpCounter (0) | 2021.04.01 |
| visualization (0) | 2020.08.05 |
| torch.utils.data.DataLoader (0) | 2020.06.20 |