Paper
openaccess.thecvf.com/content_cvpr_2018/CameraReady/0801.pdf
Code
github.com/zhirongw/lemniscate.pytorch
zhirongw/lemniscate.pytorch
Unsupervised Feature Learning via Non-parametric Instance Discrimination - zhirongw/lemniscate.pytorch
github.com
Introduction

Imagenet dataset을 기존의 supervised learning 형태로 학습시키게 되면 위와 같이 input image에 대해 유사한 class들이 softmax output에서 높은 값을 나타내는 것을 확인할 수 있다.
이는 일반적인 supervised learning이 class별로 annotation을 하여 학습시키기는 하지만 결과적으로 image간의 유사성을 스스로 학습할 수 있다는 의미를 나타낸다.
이러한 결과를 토대로 본 논문에서는 class-wise learning을 instance-wise learning 형태로 변형하여 시도한다.
Can we learn a meaningful metric that reflects apparent similarity among instances via pure discriminative learning?
그러나 이러한 방법을 사용할 경우, imagenet dataset 기준으로 class의 수가 1000개에서 1.2 million개로 늘어나게 된다.
단순히 softmax를 이용해서는 이러한 class수를 다루기 어렵기 때문에, NCE 및 proximal regularization 방법을 활용한다.
이전 논문의 경우 umsupervised learning을 통해 feature learning을 수행하면 SVM과 같은 linear classifier를 통해 classification을 수행했다.
그러나 SVM과 같은 linear classifier가 동작을 잘한다는 보장은 없다.
본 논문에서는 non-parametric한 방법인 kNN classification 방법을 사용한다.
이때, test time마다 거리 계산을 위해 training sample을 모두 embedding 시킬 수는 없기 때문에
memory bank를 활용하여 training sample을 embedding 시킨 값을 저장해놓는다.
(일반적인 classifier는 거리 계산을 위해 각 class의 대표값만을 저장해두는데, 그것이 weight이다.)

Non-parametric classifier
1) parametric classifier

일반적으로 사용하는 parametric classifier
2) Non-parametric Classifier

parametric과 다르게 instance 별로 진행한다.
이때 , v 벡터는 normalization을 적용하며, 아래와 같이 거리 기반으로 계산할 때, 유사한 class끼리 더 가깝게 embedding 되는 효과를 얻을 수 있다.

Noise-Contrastive Estimation
class수가 매우 많은 경우, softmax 계산이 어려워진다. 이와 같은 문제는 word embedding에서도 발생했었고 다음과 같이 해결 했다.
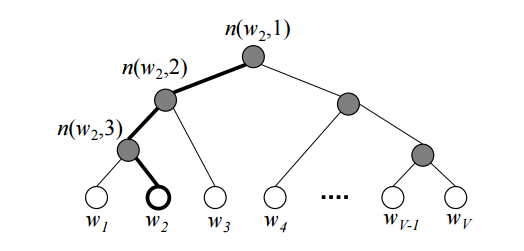
- Hierarchical Softmax: 각 단어들을 leaves로 가지는 binary tree를 하나 만들고, 해당하는 단어의 확률을 계산할 때 root에서부터 해당 leaf로 가는 길을 따라 확률을 곱해 해당 단어가 나올 최종적인 확률을 계산한다.자세한 설명은 위 그림 클릭
- Negative Sampling : 모든 단어들에 대해 Softmax를 수행하므로 계산량이 많아지는 것을 개선하기 위해 해당하는 단어와 그렇지 않은 일정 개수의 Negative Sample에 대해 Softmax를 수행한다.
- Noise-Contrastive Estimation : multi-class classification을 data sample인지 noise sample인지 판단하는 binary classification으로 바꾼다.
본 논문에서는 NCE를 사용한다. feature 를 가지는 입력 가 data sample일 posterior probability은 다음과 같다.
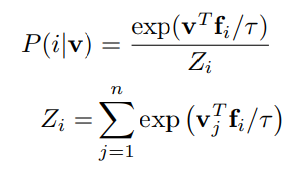

- Pn=1/n : noise distribution
- : noise sample이 data sample보다 m배 더 많다고 가정
이를 통해 만들어지는 objective function은 다음과 같다.

- : actual data distribution
- : 에서 무작위로 sampling된 이미지들의 representation
이때, 의 계산량이 여전히 많으므로 이를 Monte Carlo 근사를 이용해 계산량을 줄인다.

: 무작위 인덱스의 집합, V가 계산되지 않은 첫번째 iteration에도 근사는 유효했음 )
Proximal Regularization
일반적인 classification과 달리 본 논문은 한 class당 하나의 이미지만 가지고 학습한다. 따라서 각 epoch당 각 class는 한 번만 학습되고 매번 loss가 크게 진동한다. 이를 완화하기 위해 regularization term을 추가한다.


Weighted k-Nearest Neighbor Classifier


Parametric vs. Non-parametric So
ftmax
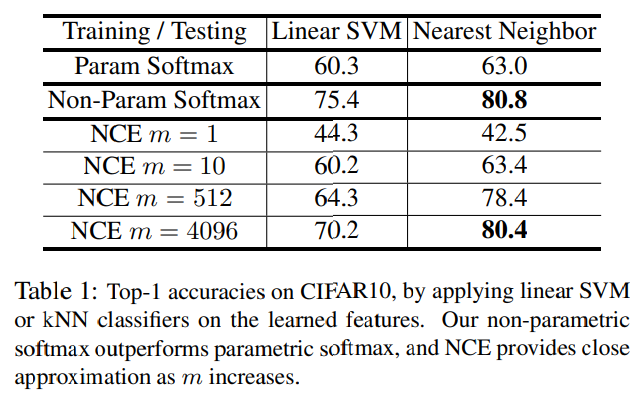

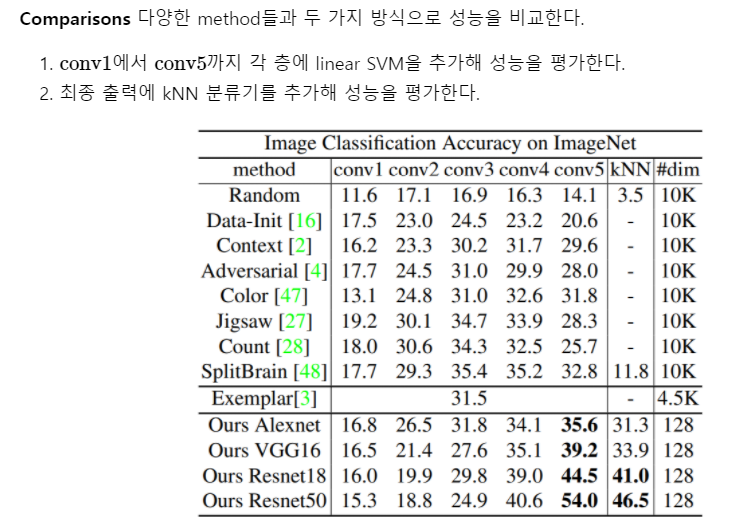
Image Classification

Qualitative case study
