Paper
https://arxiv.org/abs/1806.05236
Manifold Mixup: Better Representations by Interpolating Hidden States
Deep neural networks excel at learning the training data, but often provide incorrect and confident predictions when evaluated on slightly different test examples. This includes distribution shifts, outliers, and adversarial examples. To address these issu
arxiv.org
Code (unofficial)
https://github.com/DaikiTanak/manifold_mixup
DaikiTanak/manifold_mixup
pytorch implementation of manifold-mixup. Contribute to DaikiTanak/manifold_mixup development by creating an account on GitHub.
github.com
Introduction
- 기존 딥러닝 네트워크의 문제 중 하나는 over-confident하다는 문제가 있다.
- manifold-mixup은 기존 image-level에서 mix를 한 mix-up 논문과 달리 hidden-representation을 mix한 논문이다.
- 이러한 manifold-mixup을 활용하면 regulaizer 역할을 하기 때문에 over-confident 문제를 완화하는 효과가 있다고 주장한다.
- 또한 mix된 hidden representation부분에서 학습이 이루어지기 때문에 smoothing된 decision boundary를 얻을 수 있다고 한다.
- 이러한 결과들이 일어나는 이유로 class-representation을 flatten하기 때문이라고 이야기하고 있다.
- 이때 , flatten의 의미는 class마다 해당하는 feature의 variance의 방향이 줄어든다는 것이다.
- 본 논문에서는 flatten이 왜 일어나는지 증명하고 이를 통해서 어떠한 효과가 있는지 설명하고 있다.
( over-confident 완화 & smoother decision boundary)
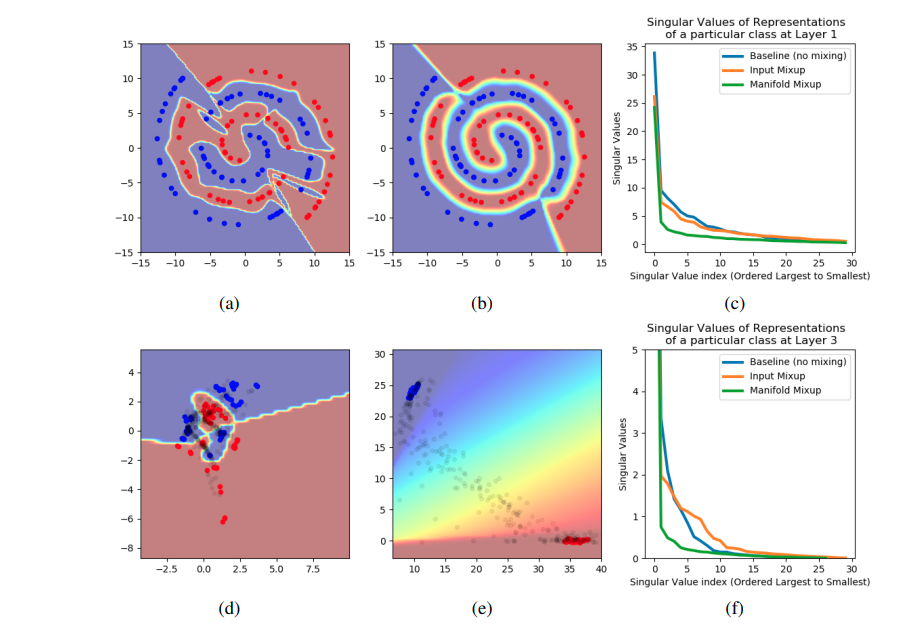
아래 그림은 위의 내용을 담고 있다.
- (a)는 기존 딥러닝 네트워크의 decision boundary를 보여주고 있다.
- (b)는 manifold mixup를 적용한 딥러닝 네트워크의 decision boundary를 보여주고 있다. (smoothing 되었음)
- (d)는 기존 딥러닝 네트워크의 Confidence 값을 나타내고 있다. -> high confidence에 집중하고 있는것을 보여줌.
- (e)는 manifold mixup을 적용하는 경우 confidece 값이 적절히 분포하게 됨을 알 수 있다.
Manifold Mixup Flattens Representations
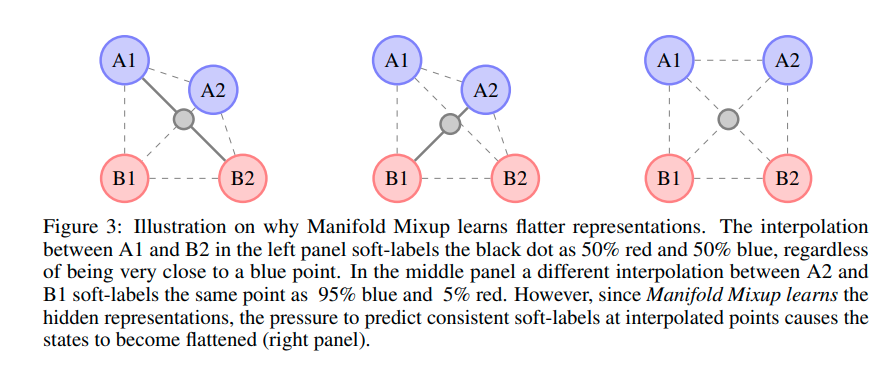
저자는 왜 Manifold-Mixup이 feature representation을 flatten하는 효과를 가져오는지 설명한다.
수학적으로 설명하는 부분은 논문에 있고, 직관적으로 설명하는 부분은 Appendix F에 있다.
위의 왼쪽 그림을 보면 A1과 B2의 mixup 결과는 회색과 같다. 그리고 A1와 B2와 mixup과의 거리를 볼 때, 50% red, 50% blue로 soft label을 정할 수 있다.
위의 중간 그림을 보면 A1과 B2의 mixup 결과는 회색과 같다. 그리고 A1와 B2와 mixup과의 거리를 볼 때, 5% red, 95% blue로 soft label을 정할 수 있다.
이때, 왼쪽과 중간 그림의 mixup 결과는 둘다 매우 비슷하다. 그러나 soft-label 결과는 매우 다른 상황이다.
network를 mixup 결과와 softlabel 결과가 비슷하게 되도록 optimization이 되게 되고 결과적으로 위의 오른쪽그림과 같이 A2를 이동시킨다. 이러한 작업의 결과로 feature representaion이 flatten 되게 된다.