기존 GAN의 형태는 다음과 같다.

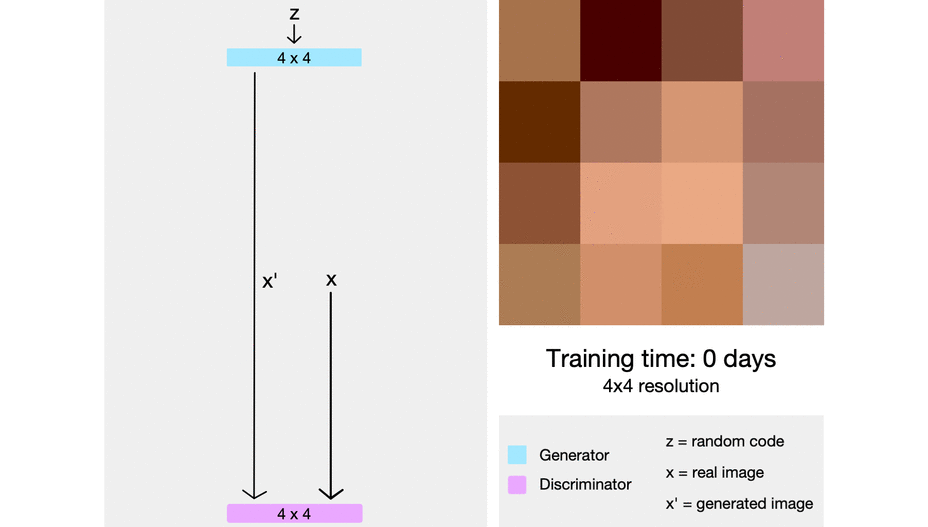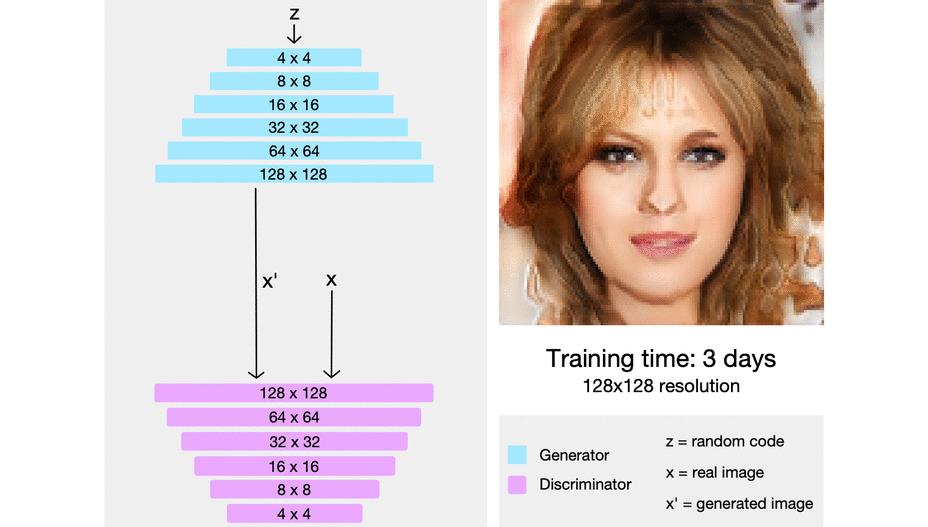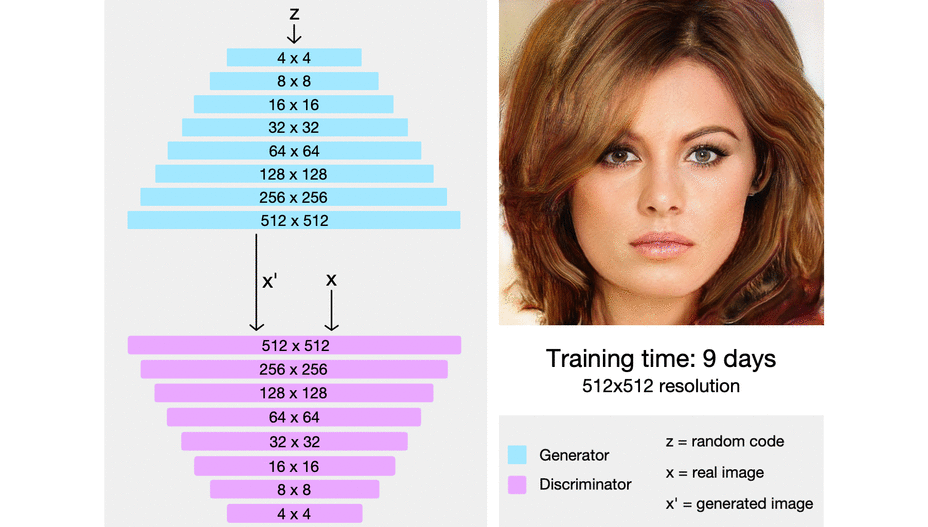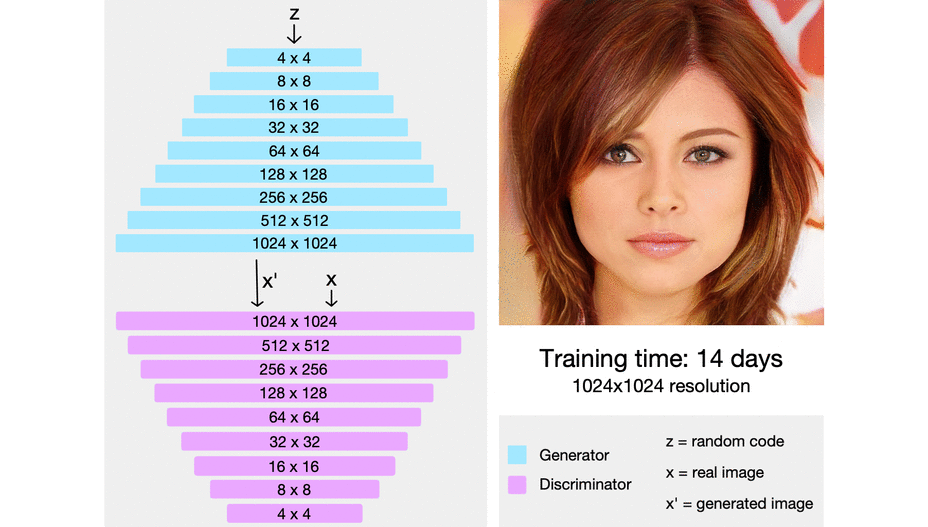
그러나 기존 GAN의 경우, 고화질 이미지를 생성하는데 어려움을 겪었고, 이를 해결한 ProGAN을 개발하게 되었다.
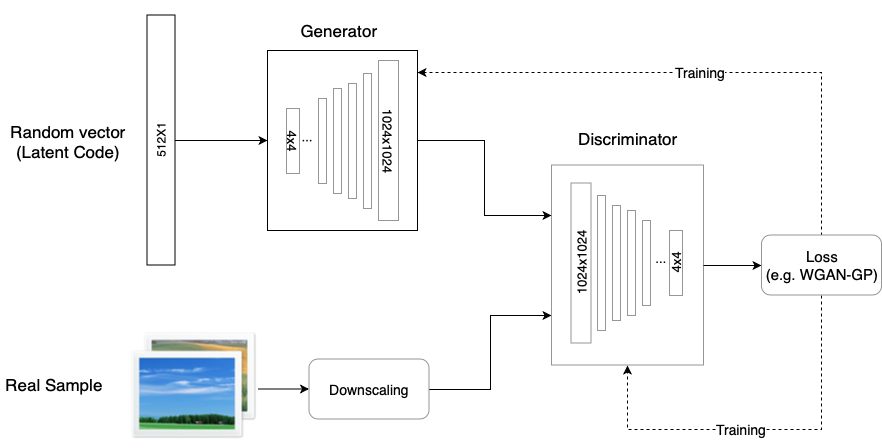
ProGAN의 경우, GAN과의 구조가 유사하나, high resolution image를 바로 high resolution으로 생성하는게 아니라, low resolution부터 생성하는 방법을 통해 고화질 이미지를 생성한다.
그러나 ProGAN을 포함한 GAN 모델은 feature가 entangle되어 있다는 문제점이 있다.
이는 다음 그림에서 잘 묘사되어 있다.
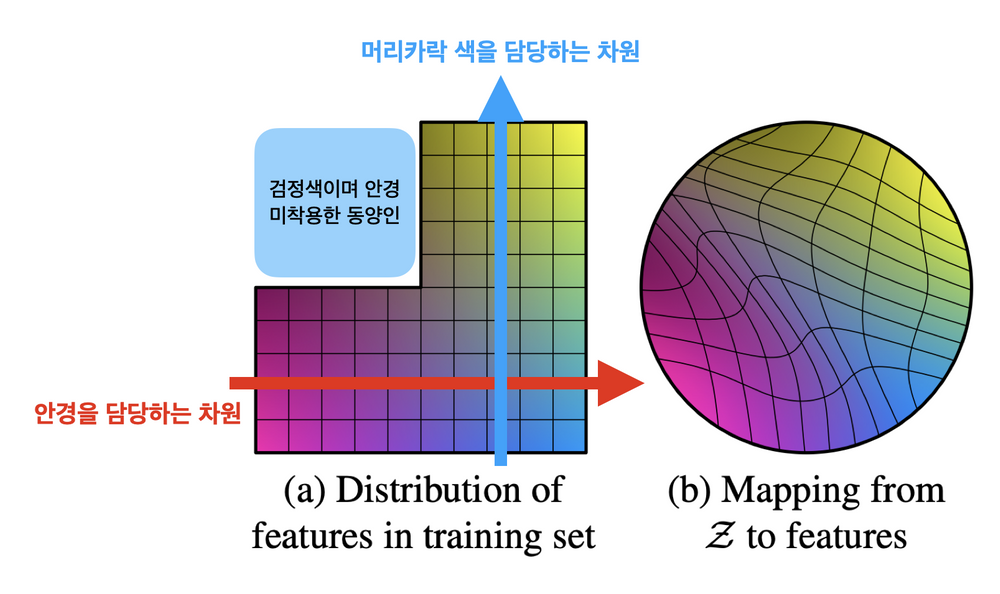
GAN의 latent space인 z space의 경우 위와 같이 각 attribute에 해당하는 요소들이 entangle되어 있기 때문에 latent space walking을 통해서 각 attribute를 변화시키는 것이 어렵다.
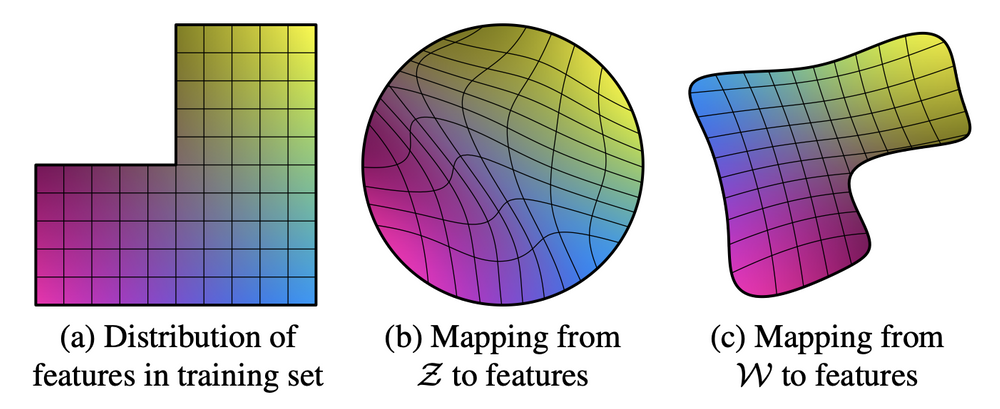
따라서 PGGAN과 같은 GAN모델에서도 style을 변화시키고 싶지만, 이미지 생성을 담당하는 latent vector의 latent space가 entangle되어 이와 같은 작업이 어렵다는 점을 해결하고 싶었고, 먼저 mapping network를 활용하여 기존의 z를 attribute들을 disentanglement 할 수 있는 W공간으로 mapping 시키는 mapping network를 도입한다.
그래서 전체적인 구조는 다음과 같다.

여기서 A는 다음과 같이 상세하게 표현이 가능하다.
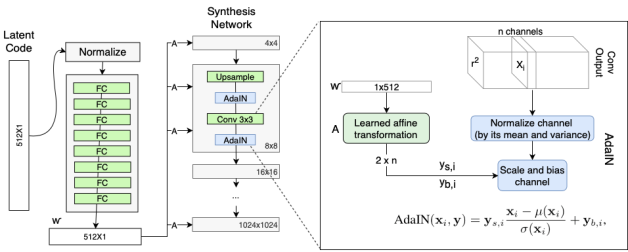
A는 FC Layer를 의미하며 w space상에서 해당 layer에서 생성하는 style을 추출하며 conv feature에 입혀준다.
각 레이어마다 다른 A FC가 있기 때문에 각각 다른 평균, 분산 값을 아웃풋으로 내어주게 되고, 이는 레이어마다 다른 스타일을 생성한다는 것을 의미한다. (레이어마다 생성하는 attribute를 disentanglement가능함.)
B는 다음과 같이 자세히 표현가능하다.
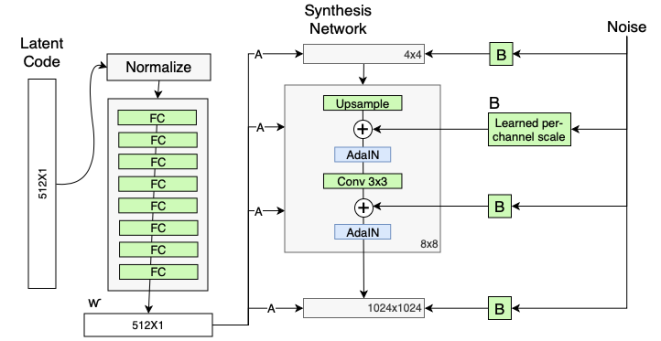
B는 noise를 추가하여 variation을 추가해주는 과정이다. 이렇게 함으로 사소한 feature(머리카락, 수염, 주름)등은 B layer 를 통한 값에 맡기고 중요한 feature(성별, 인종, 헤어스타일)은 input latent vector가 담당하도록 guide가 가능하다.
그래서 다음 그림을 통해서 각 레이어마다 style, 생성하는 feature를 disentanglement하였음을 확인할 수 있다.

Destination을 합성하는 과정에서 특정 layer의 style을 source로 치환했을 때의 합성 결과. Network 초반에는 성별, 포즈 등 coarse style이 변경되며 후반에는 머리 색 등 fine stle이 변경됨.
(source 이미지를 만들때 encoding된 style을 destination image에 적용했을 때, 결과임. 이는 각 layer별로 생성하는 style이 제대로 disentangement되었음을 말하며, 초반에는 coarse한 style 후반으로 갈수록 fine한 style이 encoding됨을 확인할 수 있음)
또한 과연 w space가 z에 비해서 disentanglement가 이루어졌는지 확인하기 위해서 perceptual path length를 제안한다.
좀 직관적으로 알아보면 latent space상에서 이동을 했을 때, 결과가 얼마나 바뀌는지 확인하는 척도라고 보면 된다.


그러나 StyleGAN의 경우, 아래와 같은 artifacts와 부자연스러운 부분이 발생하는 것으로 알려져 있다.
먼저 아래와 같은 물방울 노이즈가 발생한다.

이는 AdaIN 때문에 발생한다고 하며, 원래는 작은 spike-type distribution이 AdaIN의 normalization과정을 커져서 증가하기 때문이라고 저자는 말하고 있다. 실제로 AdaIN을 제거하면 이 물방울은 사라지는 것으로 확인되었다.
다음은 일부 feature가 얼굴의 움직임을 따르지 않는 문제이다. 아래 이미지를 보면 얼굴은 옆으로 변하지만 이의 배열은 얼굴을 따르지 않아서 부자연스럽다. 이 문제는 progressive growing으로 인해 발생한다고 한다.
왜냐하면 각각의 해상도에 해당하는 이미지가 독립적인 Generator에 의해서 생성되기 때문이다.
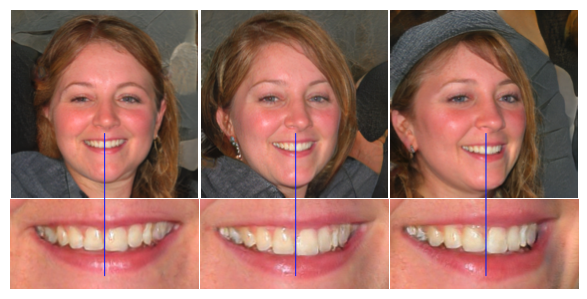
또한 Perceptual Path Length(PPL)의 분석이 이미지 품질과 연관이 있는 것으로 밝혀졌다.
(자세한 건 논문참고하자. 명확히 이해못했음)

먼저 style gan2는 다음과 같이 architecture를 수정하였다.
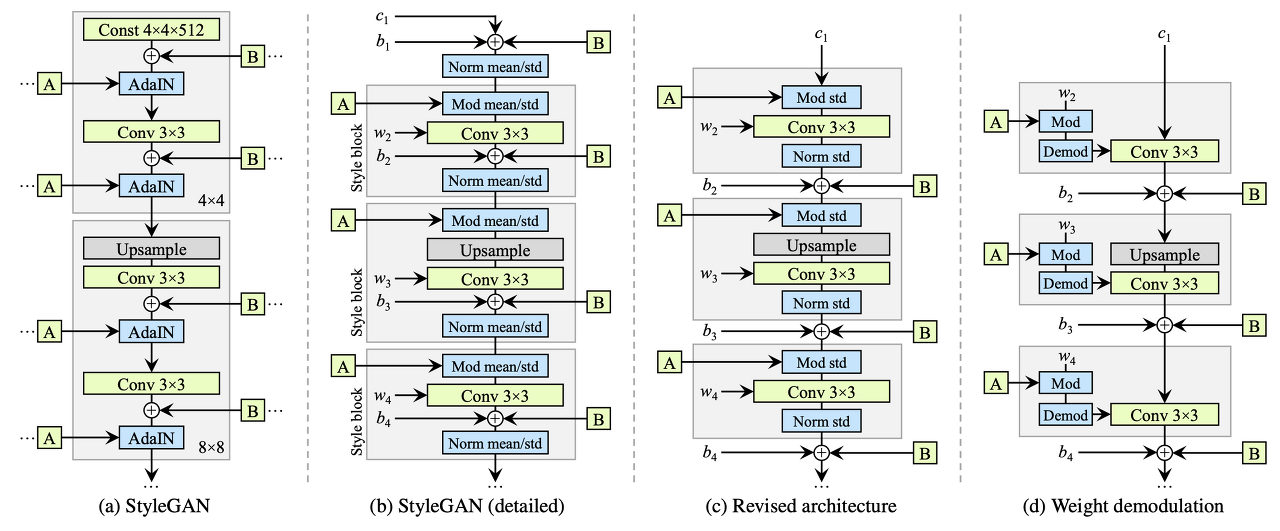
먼저 AdaIN 때문에 발생하는 droplet artifact를 해결하기 위해, AdaIn 대신 Weight Demodulation을 도입한다.
먼저 Mod mean/std와 Norm mean/std의 의미를 알아야 되는데, Mod mean/std는 그 style에 해당하는 mean값을 더하고, std값을 곱해주는 것을 의미하며, Norm은 기존의 평균값을 빼주고, 분산값을 나누어주는 연산을 의미한다.
기존 AdaIn이 Conv layer feature값에 직접 적용하게 되는데, 이와 같은 normailization 과정이 conv layer간의 feature value에 영향을 주어 conv layer 간의 관계를 해치게되고 때문에 droplet 현상이 발생한다고 주장한다.
그래서 이를 수정하게 되는데, 먼저 (c)와 같이 수정한다. 바뀐점은 mean을 modify하고 normalization하는 부분이 빠졌는데, 어차피 conv layer의 bias parameter 및 B의 noise add하는 부분 때문에 mean를 add하는 것은 의미가 없다고 보았다.
그러한 연유로 bias 및 B연산을 하는 부분 자체가 style block 바깥으로 빠져서 연산이 진행된다.
따라서 std만 modify 및 normalizaiton을 함으로 style을 적용하게 되는데, 여기서 conv feature에 이러한 연산이 적용하는 것이 droplet artifact를 발생시키는 원인이었으므로 이와 같은 mod / Demod를 Conv의 feature가 아닌 Conv의 parameter에 적용한다.
먼저 A layer를 통해서 scale factor s를 구한다. 이때 i는 feature map의 channel의 순서를 의미하며, j와k는 spatial 축의 H,W 순서를 의미한다. 즉, feature map의 각 채널 축마다 해당하는 style scale factor(분산에 해당하는..?)값을 곱해준다고 생각하면 된다. 여기가 (d)그림의 Mod과정이다.
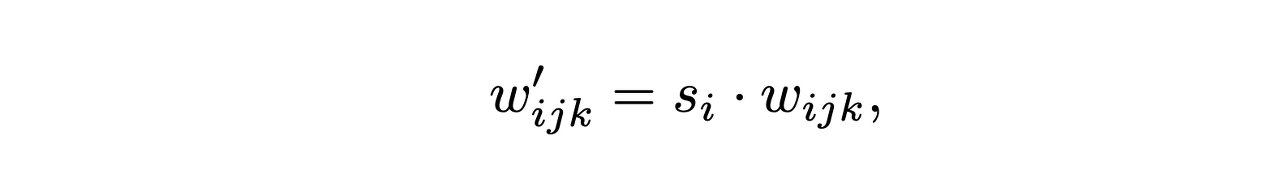
그 이후
먼저 저자는 style
https://prowiseman.tistory.com/entry/StyleGAN-StyleGAN2
StyleGAN / StyleGAN2
들어가며 StyleGAN과 StyleGAN2의 논문을 살짝 읽어보긴 했는데, 수식이 너무 어려워서 곤란해하던 중 From GAN basic to StyleGAN2 이란 포스트에 잘 정리돼 있어 위 포스트를 보고 공부하였다. 그래서 아
prowiseman.tistory.com
https://blog.promedius.ai/stylegan_2/
[GAN 시리즈] StyleGAN 논문 리뷰 -2편
StyleGAN은 PGGAN 구조에서 Style transfer 개념을 적용하여 generator architetcture를 재구성 한 논문입니다. 그로 인하여 PGGAN에서 불가능 했던 style을 scale-specific control이 가능하게 되었습니다.
blog.promedius.ai