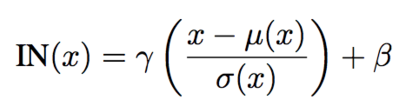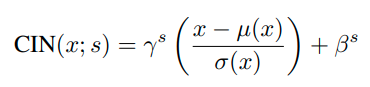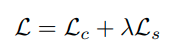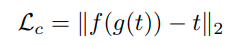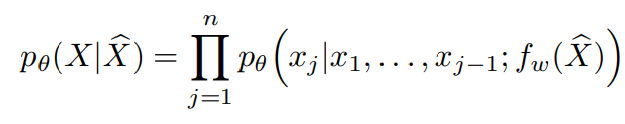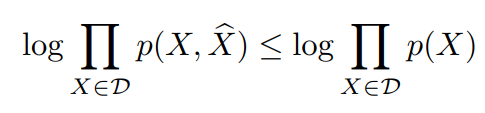그러나 기존 GAN의 경우, 고화질 이미지를 생성하는데 어려움을 겪었고, 이를 해결한 ProGAN을 개발하게 되었다.
ProGAN의 경우, GAN과의 구조가 유사하나, high resolution image를 바로 high resolution으로 생성하는게 아니라, low resolution부터 생성하는 방법을 통해 고화질 이미지를 생성한다.
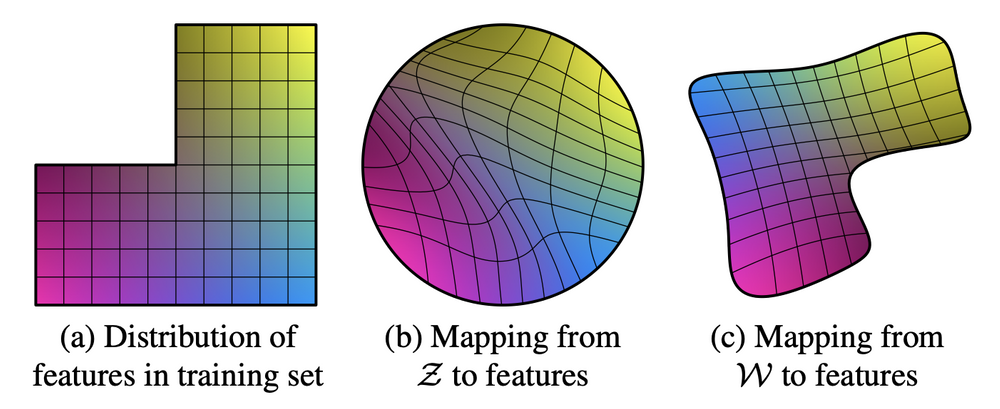
그러나 ProGAN을 포함한 GAN 모델은 feature가 entangle되어 있다는 문제점이 있다.
이는 다음 그림에서 잘 묘사되어 있다.
GAN의 latent space인 z space의 경우 위와 같이 각 attribute에 해당하는 요소들이 entangle되어 있기 때문에 latent space walking을 통해서 각 attribute를 변화시키는 것이 어렵다.
따라서 PGGAN과 같은 GAN모델에서도 style을 변화시키고 싶지만, 이미지 생성을 담당하는 latent vector의 latent space가 entangle되어 이와 같은 작업이 어렵다는 점을 해결하고 싶었고, 먼저 mapping network를 활용하여 기존의 z를 attribute들을 disentanglement 할 수 있는 W공간으로 mapping 시키는 mapping network를 도입한다.
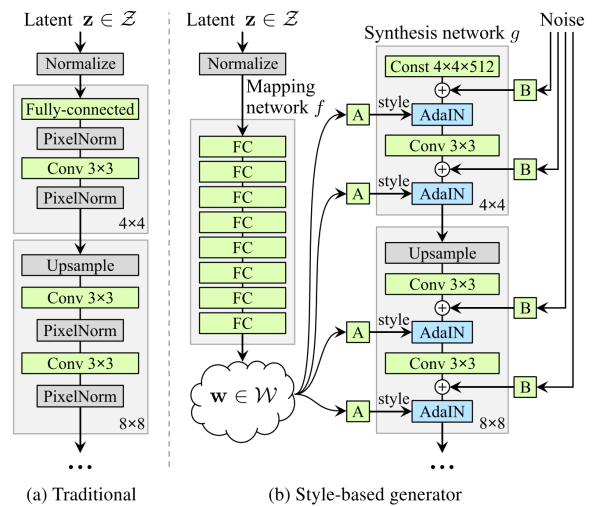
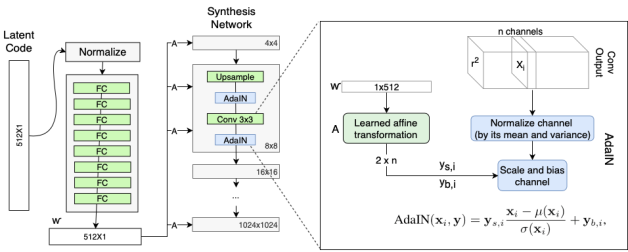
그래서 전체적인 구조는 다음과 같다.
여기서 A는 다음과 같이 상세하게 표현이 가능하다.
A는 FC Layer를 의미하며 w space상에서 해당 layer에서 생성하는 style을 추출하며 conv feature에 입혀준다.
각 레이어마다 다른 A FC가 있기 때문에 각각 다른 평균, 분산 값을 아웃풋으로 내어주게 되고, 이는 레이어마다 다른 스타일을 생성한다는 것을 의미한다. (레이어마다 생성하는 attribute를 disentanglement가능함.)
B는 다음과 같이 자세히 표현가능하다.
B는 noise를 추가하여 variation을 추가해주는 과정이다. 이렇게 함으로 사소한 feature(머리카락, 수염, 주름)등은 B layer 를 통한 값에 맡기고 중요한 feature(성별, 인종, 헤어스타일)은 input latent vector가 담당하도록 guide가 가능하다.
그래서 다음 그림을 통해서 각 레이어마다 style, 생성하는 feature를 disentanglement하였음을 확인할 수 있다.
Destination을 합성하는 과정에서 특정 layer의 style을 source로 치환했을 때의 합성 결과. Network 초반에는 성별, 포즈 등 coarse style이 변경되며 후반에는 머리 색 등 fine stle이 변경됨.
(source 이미지를 만들때 encoding된 style을 destination image에 적용했을 때, 결과임. 이는 각 layer별로 생성하는 style이 제대로 disentangement되었음을 말하며, 초반에는 coarse한 style 후반으로 갈수록 fine한 style이 encoding됨을 확인할 수 있음)
또한 과연 w space가 z에 비해서 disentanglement가 이루어졌는지 확인하기 위해서 perceptual path length를 제안한다.
좀 직관적으로 알아보면 latent space상에서 이동을 했을 때, 결과가 얼마나 바뀌는지 확인하는 척도라고 보면 된다.
그러나 StyleGAN의 경우, 아래와 같은 artifacts와 부자연스러운 부분이 발생하는 것으로 알려져 있다.
먼저 아래와 같은 물방울 노이즈가 발생한다.
이는 AdaIN 때문에 발생한다고 하며, 원래는 작은 spike-type distribution이 AdaIN의 normalization과정을 커져서 증가하기 때문이라고 저자는 말하고 있다. 실제로 AdaIN을 제거하면 이 물방울은 사라지는 것으로 확인되었다.
다음은 일부 feature가 얼굴의 움직임을 따르지 않는 문제이다. 아래 이미지를 보면 얼굴은 옆으로 변하지만 이의 배열은 얼굴을 따르지 않아서 부자연스럽다. 이 문제는 progressive growing으로 인해 발생한다고 한다.
왜냐하면 각각의 해상도에 해당하는 이미지가 독립적인 Generator에 의해서 생성되기 때문이다.
또한 Perceptual Path Length(PPL)의 분석이 이미지 품질과 연관이 있는 것으로 밝혀졌다.
(자세한 건 논문참고하자. 명확히 이해못했음)
먼저 style gan2는 다음과 같이 architecture를 수정하였다.
먼저 AdaIN 때문에 발생하는 droplet artifact를 해결하기 위해, AdaIn 대신 Weight Demodulation을 도입한다.
먼저 Mod mean/std와 Norm mean/std의 의미를 알아야 되는데, Mod mean/std는 그 style에 해당하는 mean값을 더하고, std값을 곱해주는 것을 의미하며, Norm은 기존의 평균값을 빼주고, 분산값을 나누어주는 연산을 의미한다.
기존 AdaIn이 Conv layer feature값에 직접 적용하게 되는데, 이와 같은 normailization 과정이 conv layer간의 feature value에 영향을 주어 conv layer 간의 관계를 해치게되고 때문에 droplet 현상이 발생한다고 주장한다.
그래서 이를 수정하게 되는데, 먼저 (c)와 같이 수정한다. 바뀐점은 mean을 modify하고 normalization하는 부분이 빠졌는데, 어차피 conv layer의 bias parameter 및 B의 noise add하는 부분 때문에 mean를 add하는 것은 의미가 없다고 보았다.
그러한 연유로 bias 및 B연산을 하는 부분 자체가 style block 바깥으로 빠져서 연산이 진행된다.
따라서 std만 modify 및 normalizaiton을 함으로 style을 적용하게 되는데, 여기서 conv feature에 이러한 연산이 적용하는 것이 droplet artifact를 발생시키는 원인이었으므로 이와 같은 mod / Demod를 Conv의 feature가 아닌 Conv의 parameter에 적용한다.
먼저 A layer를 통해서 scale factor s를 구한다. 이때 i는 feature map의 channel의 순서를 의미하며, j와k는 spatial 축의 H,W 순서를 의미한다. 즉, feature map의 각 채널 축마다 해당하는 style scale factor(분산에 해당하는..?)값을 곱해준다고 생각하면 된다. 여기가 (d)그림의 Mod과정이다.
Gram matrix를 feature map간의 관계(유사도)를 나타낸 행렬로서 style을 담고 있다는 것이 실험적으로 밝혀졌고, gram matrix뿐만 아니라 feature map의 평균과 분산이 style에 대한 정보를 가지고 있다고 실험적으로 밝혀지게 되었다.
이러한 연구는 추후 style transfer 연구에서도 나타나게 되는데 순서는 다음과 같다.
먼저 우리가 자주 사용하는 batch norm을 살펴보자.
batch norm의 경우, 학습과정에서 생기는 internal covariant shift를 해결하기 위해 만들어진 기법으로, 위 그림처럼 batch size의 전체를 기준으로 각 채널별로 H,W에 대한 평균, 분산을 구해서 표준화(standardization)를 해서 학습을 한다.
instance norm의 경우, 이러한 표준화를 batch size가 아닌 instance별로 행하는 것을 의미하며, instance별로 각 채널의 평균 분산을 구해서 그 값을 이용해 각 채널을 표준화 해주는 것을 의미한다.
여기서 instance norm의 이야기를 왜 하냐면 Ulyanov가 쓴 논문에서 기존의 style transfer task에서 batch normalization을 instance normailzation으로 바꾸는 것만으로 style transfer task의 성능이 크게 향상되었기 때문이다.
이러한 결과에 힘입어 Conditional Instance Normalizatrion 또한 제시되었다.
CIN은 affine parameter γ,β를 style에 관계없이 하나만 학습시키는 것이 아니라, style별로 다르게 학습시키는 방법을 택한다. training할때, style image를 s개의 index 묶음으로 묶은다음,
그렇기 때문에 Adain은 content 이미지 feature map에다가 style feature map의 평균과 분산을 적용함으로서, style을 변경해주는 방법이다. 그렇기 때문에 s가 바로 style의 개수라고 볼 수 있는데, 결과적으로 놀라운 일은 네트워크가 같은 convolution parameter를 사용하면서, affine parameter만 변경한것으로 다른 스타일을 생성한다는 점이었다.
이러한 실험 결과들에 힘입어 instance normalization 과정 자체가 style을 normalization하는 것이라고 생각하게 되었다.
그리고 affine parameter를 적용함으로, 새로운 style을 적용가능하다고 생각하게 되었다.
그렇다면 CIN처럼 스타일의 개수를 한정하여 만들지 말고, affine parameter를 각 스타일마다 적용하면 어떻게 될까?
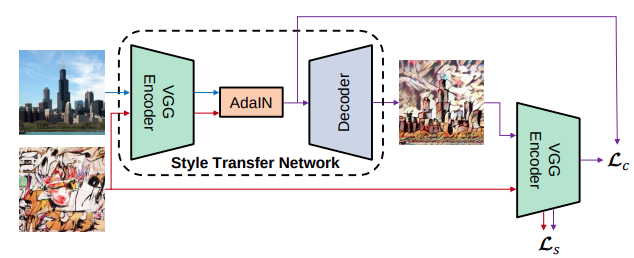
그게 바로 AdaIN(Adaptive Instance Normalization)이다.
AdaIN은 기존의 Instance Norm의 affine parameter를 하나의 값으로 고정하거나, 한정된 개수 (CIN : 32개)로 만드는 것이 아닌 style 각각에 대해서 추출하여 적용한다.
이를 식으로 표현하면 다음과 같다.
이를 직관적으로 설명하면 다음과 같이 설명이 가능하다.
직관적으로, 우리가 feature channel을 특정한 스타일의 brushstrokes 을 detect하자고 하자. 이러한 stock는 이 feature를 위한 high average activation 를 생성할 것이다. AdaIN에 의해서 생성된 output은 contents image의 spatial structure를 유지하면서 이 feature를 위한 같은 high average activation를 가지게 될 것이다. 이러한 brushstrokes feature는 Fedd-forward decoder를 통해 iamge space로 inverted될 것이다. 이러한 feature channel의 variance는 더 미묘한 style imnformation을 encode할 수 있을 것이고, 이것은 또한 AdaIN output으로 전달되고, 최종적인 output image에 전달될 것이다.
정리하자면, AdaIN은 channel-wise mean and variance라는 feature statistics를 transfering함으로서 feature space상에서 style trasnfer를 수행한다.
이때 Loss function은 다음과 같이 구성된다.
여기서 L_c (content Loss)는 다음과 같다.
이때 g(t)는 decoder를 통해서 나온 이미지를 의미하며, 이를 VGG encoder에 다시 통과시켜 feature 형태로 변환한다.
그리고 기존의 AdaIN을 통과해 나온 결과 feature와 L2 Loss를 줌으로 decoder를 학습시킨다. (encoder는 고정)
Style Loss는 다음과 같이 적용한다.
ϕi.는 VGG-19의 i번째 레이어이다. 스타일로스에서 사용한 레이어는 relu1 1, relu2 1, relu3 1, relu4 1 이다. 이 역시 간단하게 설명하자면, 원래 스타일 s를 인코더에 넣었을 때의 i번째 feature ϕi(s)의 평균과 t를 디코더에 넣고 이를 다시 encoder에 넣었을 때의 i번째 Feature ϕi(g(t)) 의 평균(μ)과 표준편차(σ)를 최소화 시키는 방법으로 스타일 로스를 구한것이다.
1) low-image detail에 집중해서 생성하는 경향 (texture) , 이에 비해 물체의 shape는 잘생성하지 못함
2) inference time때 pixel 하나씩 생성하는데, 이것이 시간이 많이 들고, computationally cost가 크다.
이러한 단점들을 해결하기 위해서 본 논문에서는 auxiliary variables를 도입한다.
1번의 low-image detail에 집중하는 문제는 Grayscale Pixel CNN을 도입함으로 해결한다.
Grayscale pixel의 경우 이미지의 texture정보가 상대적으로 사라지기 때문에 shape와 같은 high-level image detail에 집중할 것이고, 그렇기 때문에 original pixel CNN의 경우, low level image detail를 생성하고, gray-scale pixel CNN의 경우 high level image detail을 생성하여 task decoupling이 이루어질것이라는 생각이다.
또한 2번의 기존 pixel CNN의 computationally cost문제를 해결하기 위해 Pyramid Pixel CNN을 도입한다. 이는 기존 방법보다 더 간편한 inference형태를 제공한다.
Method
기존의 pixel CNN은 다음과 같이 chain rule을 이용해서 i-th pixel의 conditional probability를 계산한다.
본 논문의 main contribution은 다음과 같이 auxiliary variable을 도입했다는 점이다.
이는 다음과 같이 수식적으로 표현할 수 있다.
이때 X_hat이 고정된 값인 경우 PixelCNN이 pixel을 예측하는 방식을 그대로 사용하면 되고, 확률모델 p(X_hat)으로 표현되는 경우, 먼저 p(X_hat)을 계산한 후에 p(X|X_hat)을 곱해주는 형태로 pixel을 생성가능하다.
이때 p(X_hat)은 다음과 같은 조건을 만족시키는 형태로 만든다.
1) p(X_hat)은 Pixel CNN형태와 같은 type의 모델로 만들 수 있게 한다.
2) X_hat은 deterministic function으로 X -> X^ 계산이 되는 형태를 사용한다.
이렇게 하면 장점들이 있는데 바로 (2)번 특성을 이용하면 p(X^|X) 의 형태가 peaked distribution 형태가 되고, training과정에서 효율적으로 가능해진다.
일단 먼저 log p(X,X^)은 위와 같이 decomposition이 가능하고, 이때 parameter가 겹치지 않기 때문에 parallel learning이 가능하다. 그리고 이렇게 decomposition 했을 때, 아래와 같이 lower bound를 수식으로 표현이 가능하다.
이때 p(X, X^)는 p(X^|X)p(X)로 표현할 수 있고, p(X^|X) 는 X->X^간의 관계가 deterministic하게 표현되는 경우 peaked distribution (각 X에 대해서 1에 가깝게..) 형태가 되므로 low bound도 최대가 되는 장점이 있다.
이와같은 조건을 만족하는 aux variable로 본 논문에서는 2가지를 제시한다.
1) Grayscale Pixel CNN
Grayscale pixel CNN은 aux variable로 4-bits gray scale이미지를 활용하는 것이다.
이를 활용하면 앞서 제시했던 기존의 PixelCNN이 이미지의 low-level detail (texture)만 잘 생성하는 문제를 보완할 수 있기 때문에 활용한다고 한다. 왜냐하면 gray scale이미지의 경우 이미지의 texture나 color정보가 사라지기 때문에 shape와 같은 high-level detail만 상대적으로 남기 때문이다.
따라서 p(X^)는 이미지의 global property를 포함하게 되고, P(X|X^)은 이미지의 low level property를 포함해서 P(X)를 생성하게 된다.
2) Pyramid PixelCNN
기존의 pixelCNN 모델은 다음과 같은 단점이 있다.
첫번째 Pixel의 경우에는 어떤 information도 제공받지 못하는 반면에 마지막 pixel의 경우 모든 pixel의 정보를 제공받아서 생성된다. 이러한 assymmetic한 점을 보완하면 생성이 더 잘될것이라고 저자는 생각했다.
또한 기존 PixelCNN은 recurrent한 속성때문에 inference 속도가 느리고 computational cost 또한 크다.
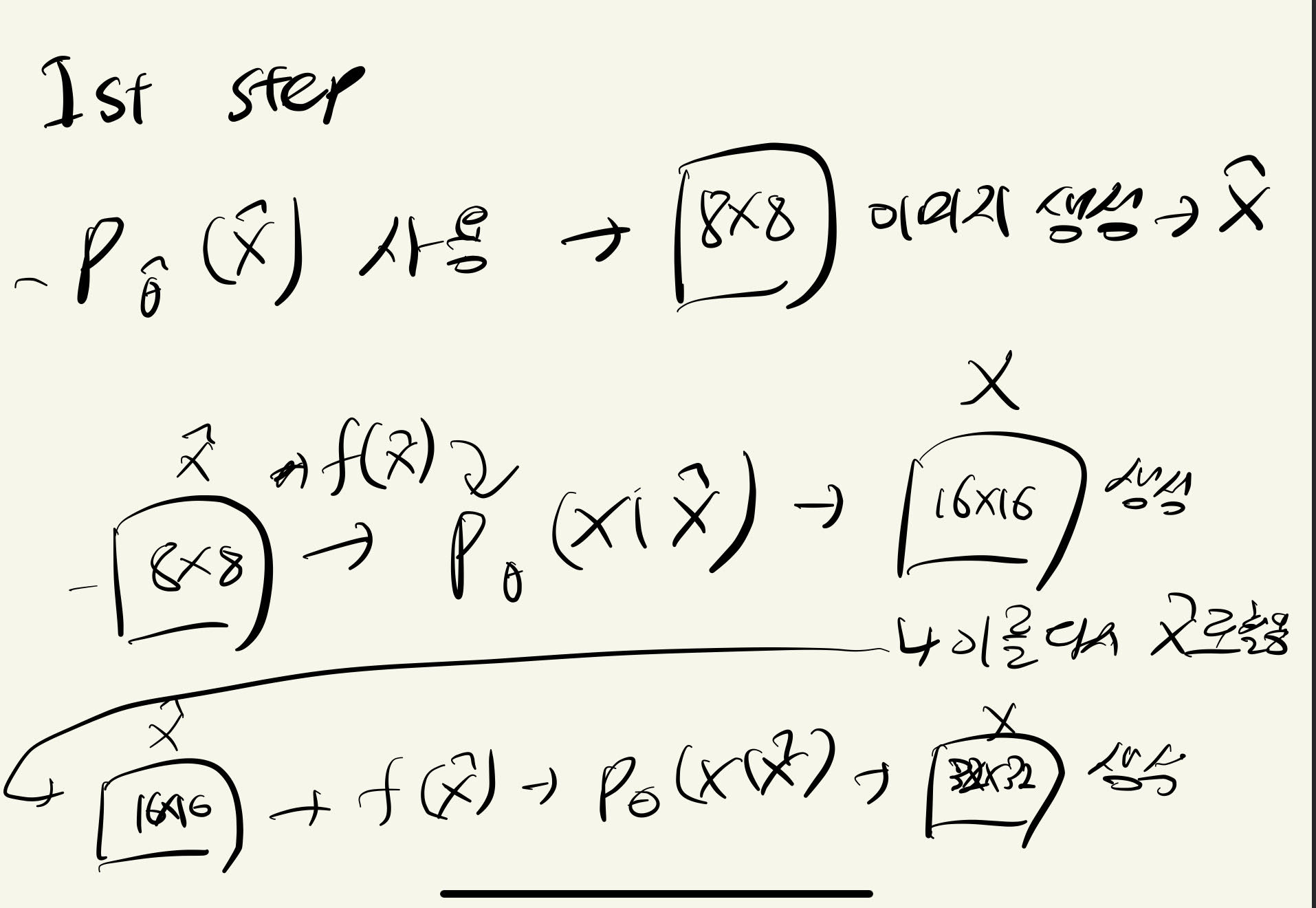
이를 보완하기 위해서 저자들은 low resolution image를 aux variable로 사용한다.
이렇게 low resolution image를 활용하면 이미지의 spatial한 부분에서 전체적인 정보를 활용할 수 있기 때문에 기존 PixelCNN의 문제인 receptive field가 작다는 문제및 assymetric문제를 해결할 수 있다.
이때 과정은 다음과 같이 그림으로 표현할 수 있다.
이때, embedding function을 deep한 네트워크를 사용하면 나머지 P(X^) , P(X|X^)모델은 light-weight를 사용해도 될거라고 저자들은 가정한다. 이렇게하면 speed의 향상을 가져올 수 있는데, 왜냐하면 computational cost가 큰 embedding function(deep NN을 쓰므로)은 pixel단위로 계산이 이루어지는 것이 아니면 conv연산 전체를 행하기 때문이다.
그리고 each pixel로 생성하는 과정의 모델인 P(X|X^)의 경우 light-weight 모델이기 때문에 빠르게 연산이 행해지고 이는 속도의 향상을 가져온다.
Details
기본적으로 conditional model p(X|X^)의 구현은 다음과 같이 이루어진다.
embedding function f(X^)의 결과를 network의 residual block의 결과에 bias값으로 넣어준다.
embedding function f(X^) 또한 PixelCNN++의 architecture와 거의 동등하게 사용한다.
그러나 The main difference is that we use only one flow of residual blocks and do not shift the convolutional layers outputs, because there is no need to impose sequential dependency structure on the pixel level.
Receptive field는 conv 커널의 결과가 실제 이미지에서 얼마나 img의 많은 영역의 정보를 담고 있는지 지칭하는 용어이다. 예를들어 5x5 이미지가 맨 처음에 있다고 하면, 그림에서 보는 것처럼 3x3 conv filter를 지나가고 나면 Layer2에서는 초록색 한점이 되고, receptive field는 3x3이 된다. (Layer 2의 초록색 한점 기준) 그리고 이렇게 나온 결과인 Layer2의 노란색 영역에 대해서 다시 conv filter 3x3를 적용하게 되면, 마지막 Layer3의 결과가 나오게 되는데 이 경우는 Layer2의 노란색영역의 Receptive field가 Layer1의 5x5영역이고, 이를 모두 압축한 결과이기 떄문에 결론적으로 5x5영역의 receptive field를 가지게 된다.