Paper
Learning Open Set Network with Discriminative Reciprocal Points
Open set recognition is an emerging research area that aims to simultaneously classify samples from predefined classes and identify the rest as 'unknown'. In this process, one of the key challenges is to reduce the risk of generalizing the inherent charact
arxiv.org
Introduction

대부분의 현재 classfication method들은 "What is a cat"에 집중한다. 그래서 cat의 가장 representative한 feature을 찾도록 학습한다. 본 논문에서는 "What is not a cat" 에 집중하는 학습방법을 사용한다. 그래서 non-cat data에 대한 새로운 representation Point를 찾도록 학습한다. 그리고 그것을 Reciprocal Point라고 명명한다.
그래서 본 논문에서 제안하는 method를 Reciprocal Point Learning (RPL) 이라고 한다.
RPL은 open space risk를 줄이는 방법이다. 이때, open space란 다음과 같다.
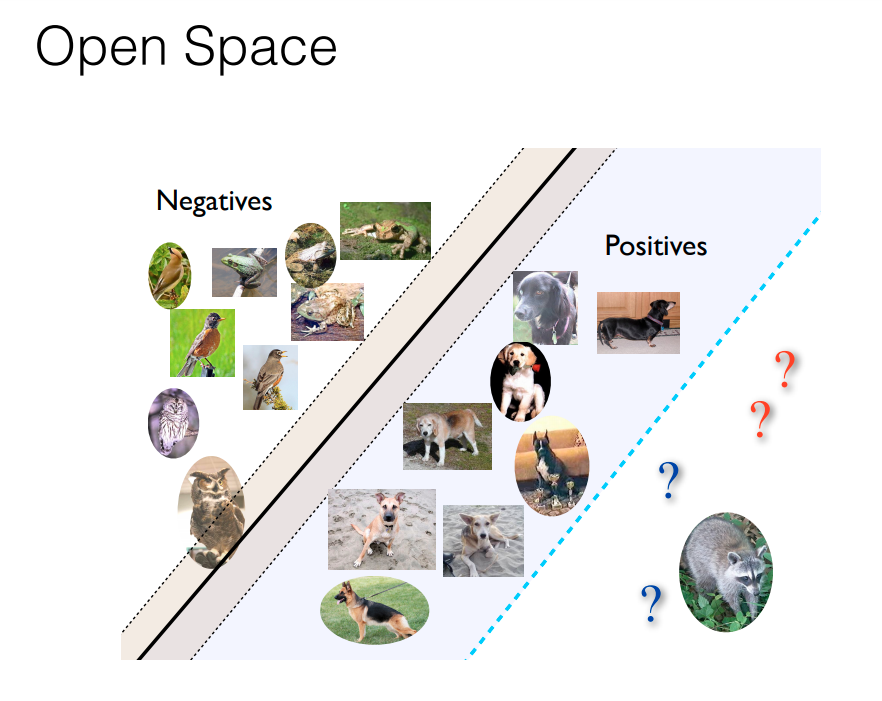


(분모는 위의 그림 참고)
즉, embedding space에서 known data가 embedding되는 공간을 제외한 space를 open space라고 한다.
그리고 open space risk는 embedding space의 모든 공간 중에서 open space가 차지하는 비중이다.
RPL은 이 open space risk를 줄이기 위한 방법이다. 이때, known class에 대한 reciprocal point를 학습시킴으로서 open space risk를 줄일 수 있다.
상세한 과정은 다음과 같다.

reciprocal point를 현재 학습하는 known class와 다른 extra-class를 이용해서 학습을 하고, input의 구분은 embedding feature와 reciprocal point의 차이를 이용해 구분한다.
학습과정에서는 reciprocal point를 이용해 all known class들이 reciprocal point에 push되고 pull되는 과정이 반복되게 된다.
결과적으로 embedding space는 bounded range에 갇히게 된다.
이러한 방법을 통해 기존의 딥러닝 모델의 문제였던 unknown input에 대한 high confidcence가 나오는 문제를 boundary를 제한함으로써 해결할 수 있다.
이러한 방법으로 known sample만 traing stage때 사용할 수 있지만, reciprocal point를 이용해 known과 unknown을 분리할 수 있다.
Reciprocal Point Learning
1) Preliminaries
Open set recognition problem definition
labeled data D_L이 N known classes들과 있다고 생각해보자. 이때, 특정 category k에 해당하는 positive training data를
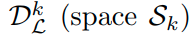
특정 category k를 제외한 다른 class들에 대한 training data를

potential unknown data를

1-class open set recognition probelm 은 다음과 같은 optimization식을 optimization 하는 것이다.

이때 R^k는 expected error이다. α는 regularization parameter이다.
R_ε 는 known data의 empirical classfication risk이다.
R_o 는 open space risk이다.
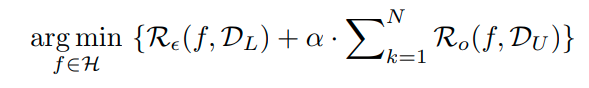
multi class classification에서는 위와 같이 표현할 수 있다.
Reciprocal Points for Classification
category k의 reciprocal point는 다음과 같이 표현할 수 있다.

이때 M은 각 class의 reciprocal point의 수이다. 이때 P^k는 sub-dataset

k class가 아닌 dataset 및 unknown dataset에 대한 latent representation의 set 이라고 생각될 수 있다.
이때, 특정 category k에 대해 기준으로 learninig하는 prototype or center loss와 달리,
위의 기준에 따라 reciprocal point를 설정하는 것은 S_k보다는 O_k에 있는 sample로 설정하는 것이 적절하다.
(S_k는 특정 class k의 sample이 차지하는 space, O_k는 특정 class k를 제외한 나머지 class에 대한 embedding space 및 unknown class들의 embedding space를 합친 공간이다.)
이는 다음과 같이 표현이 가능하다.
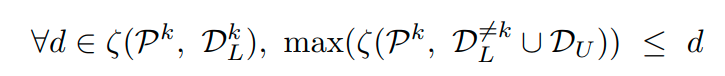
이때 ,
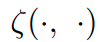
는 two sets의 모든 sample에 대한 distances들의 set이다.
즉 위의 식을 해석하면 다음과 같다.
특정 class k data와 k에 대한 reciprocal point P에 대한 모든거리를 d라고 표현할때,
class k의 reciprocal point와 class k의 제외한 데이터 및 unknown data간의 distance들의 max값을
d보다 작게 하는 것을 의미한다.
즉 한마디로 reciprocal point를 특정 class k에 대한 data들의 거리보다 k가 아닌 data들간의 거리가 가까운 점이어야 한다는 것이다.
어찌되었든 openset learning은 known space와 unknown space를 최대한 분리시키는 것이다.
이를 위해서 class k와 reciprocal point에 대한 공간을 최대한 분리시킨다.
이를 위해서 sample x가 있고, reciprocal point P_k가 있을 때, 둘간의 거리는 sample x가 embedding 된 위치와 M개의 reciprocal point와의 distance의 평균으로 정의한다.

이때, sample x가 category k 속할 확률인 reciprocal 간의 거리에 비례하게 된다.

즉 거리가 클수록 class k에 속할 확률이 높으므로 다음과 같이 정의가 가능하다.
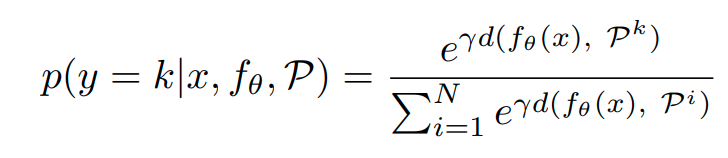
γ는 hyper parameter이다. γ 는 probability의 assign되는 정도를 뜻한다. (클수록 크고 급격한 확률로 속하게 됨)
Loss function은 다음과 같다.

이러한 방법을 통해 closed space와 open space의 interval을 크게 만들 수 있으며,
또한 아래 empirical classfication risk 또한 줄일 수 있다.

Reducing Open Space Risk
open set recognition 문제를 풀기 위해서, reciprocal loss를 open space risk를 줄이기 위해서도 같이 사용한다.

open space는 category k를 제외한 다른 class sample이 embedding되는 space

unknown sample들이 embedding되는 space
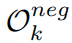
두개로 나누어 생각할 수 있다.
그러므로 모든 known class의 open space를 고려한 global open space 다음과 같다.

이때, maximum entropy 이론에 따르면, 따로 prior 조건을 주지 않은 unknown sample x_u는
well-trained closedset disciriminant function에는 equal probability를 가지게 된다.
(최종 softmax 확률값 uniform하게 나온다.)
이것의 의미는 embedding space상에서 unknown sample은 중앙에 위치하는 경향을 가진다는 의미이다.
이는 다음과 같은 실험 결과에서 확인 가능하다.
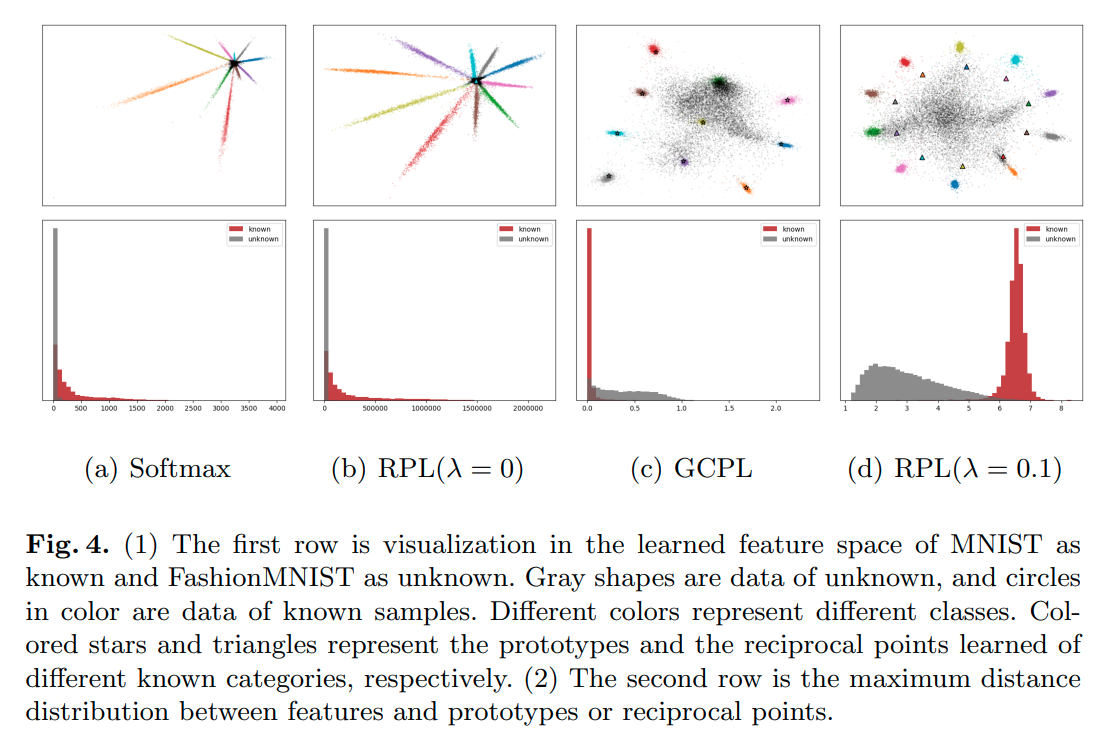
이때, open space를 직접적으로 어떠한 공간으로 bounding 시키는 것은 어려운일이다. 왜냐하면 unknown sample의 범위가 너무나도 넓기 때문이다.
그러나 class k에 대한 space S_k와 나머지 space O_k를 상호보완적(complementary)라고 생각하면, 다음과 같이 간접적으로(indirectly) bounding이 가능하다.
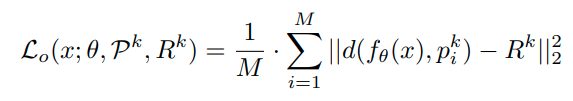
이때, R_k는 learnable margin이다. 이때 위 식을 minimizing하는 것은 다음 두식을 최대한 같게 만드는 것과 같은 의미이다.
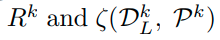
이유는 위 식에서 x의 embedding된 위치와 reciprocal point와의 거리가 바로

이 식이기 때문이다. (집합 인 것만 다름)
그러므로 다음과 같이 된다.
위 식때문에,

와 같이 된다. (d와 R^k가 최대한 가까워지므로)
이렇게 하면 reciprocal point P_k를 중심으로 margin R^k를 가지는 boundary가 형성된다.
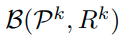
이 bounded space를 이용해 global unknown space를 최대한 bounded할 수 있다.
Learning Open Set Network
결론적으로 loss식은 다음과 같이 된다.

위 식의 의미는 classfication loss식에서는 k class의 reciprocal point랑 k class에 대한 sample의 거리를 크게 만드는 역할을 한다. open space에 대한 regularization 식은 단순히 거리를 크게 만드는 것이 아니라 특정 boundary로 embedding space를 제한하는 역할을 한다.
loss 식을 통해 아래 그림과 같이 embedding space가 형성된다.

이때까지 설명한 내용을 알고리즘으로 나타내면 다음과 같다.

Experiments
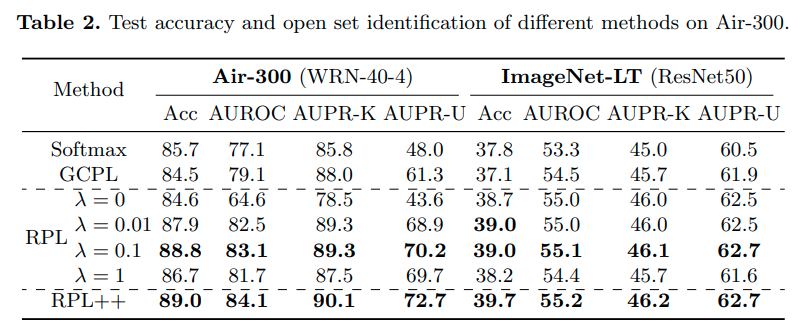
RPL++은 RPL training을 위해 GCPL을 같이 사용한 경우를 말한다.

1) Experiments for Open Set Identification

2) Experiments for Open Long-Tailed Recognition
Evaluation metric
AUROC 및 AUPR을 사용, AUPR-Known과 AUPR-Unknown은 각각 known과 unknown을 positive로 놓았을때, precision-recall 값을 말한다.
Further Analysis
1) RPL vs Softmax
Reciprocal의 classification loss term만 사용할 경우, 일반적인 cross entropy loss term과 큰 차이가 없다.

그러나 open space에 대한 loss term을 추가하는 경우, high confidence를 발생시키는 unknown sample에 대한
risk를 감소시키고 known sample이 embedding space의 중앙에 위치하여 발생하는 known sample과 unknown sample간의 overlap 또한 막을 수 있다.
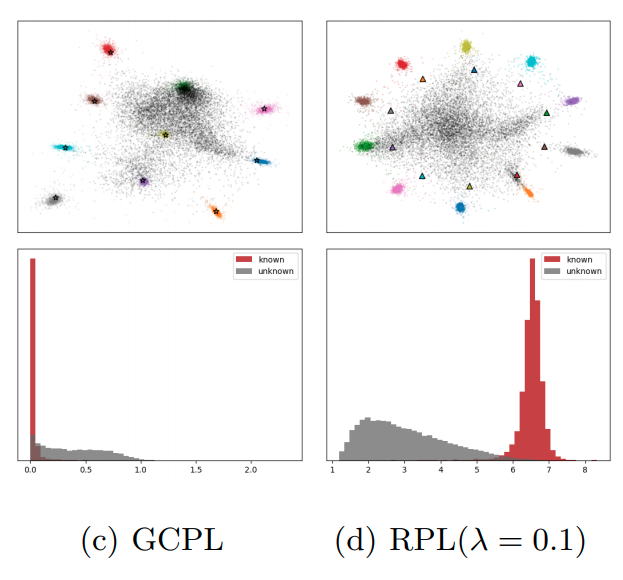
2) RPL vs GCPL
GCPL경우 center loss처럼 prototype loss를 적용한 방법이다. 이러한 loss를 적용하는 경우 각 class의 sample들이 한 곳으로 뭉치는 효과가 있으나, embedding space의 주변부로 최대한 멀어지는 효과는 가지지 못한다. known class sample들을 최대한 주변부로 밀어내는 RPL에 비해 known class sample과 unknown class sample이 겹치는 것을 볼 수 있다.
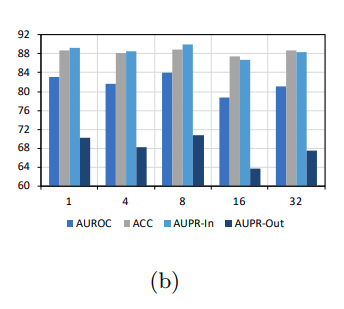
3) Margin & λ.
open space loss를 λ를 통해 조절이 가능하다. 이를 통해서 margin 또한 조절이 가능하다.
dataset 마다 적절한 margin은 다르며, 너무 작게 margin을 설정할 경우 classificaiton 성능이 떨어진다.

4) Experiments with Multiple Reciprocal Points.
Reciprocal point의 수에 대한 변화이다.
'Paper > Openset recogniton' 카테고리의 다른 글
| Open Set Learning with Counterfactual Images : ECCV 2018 (0) | 2021.07.07 |
|---|---|
| Generative OpenMax for Multi-Class Open Set Classification : BMVC 2017 (0) | 2021.06.29 |
| Toward Open Set Deep Networks : CVPR 2016 (0) | 2021.06.28 |
| Learning Placeholders for Open-Set Recognition: CVPR 2021 Oral (0) | 2021.05.21 |
| OLTR: Large-Scale Long-Tailed Recognition in an Open World : CVPR 2019 (0) | 2020.12.31 |