Paper
Code
https://github.com/lwneal/counterfactual-open-set
lwneal/counterfactual-open-set
Counterfactual Image Generation. Contribute to lwneal/counterfactual-open-set development by creating an account on GitHub.
github.com
Open Set Learning with Counterfactual Images는 openset example을 생성해 학습에 이용하여 Openset을 걸러내는 아이디어를 사용한 논문 중 하나이다.
high-level로 아이디어를 설명하면 기존 Know class sample을 이용해서 known samplerhk 유사하지만 known sample은 아닌 openset example을 생성하여 이를 openset recognition에 활용한다.

G-openmax와 다른 점은 Vanila GAN을 이용해서 openset example을 생성한 것이 아니라 encoder-decoder 형태의 GAN을 사용했다는 것이다.

본 논문에서 사용하는 Generative model은 다음과 같이 Loss function이 구성된다.
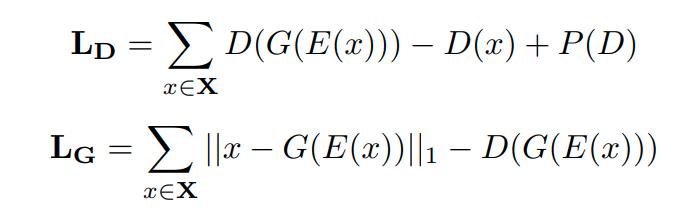
L_D 에서 D(G(E(x))) 는 생성된 image가 discriminator에 들어갔을 때 loss값을 의미한다. 그리고 D(x)는 real image가 discriminator안에 들어갔을때 loss값을 의미한다.
수식은 잘 이해가 안되서 code를 살펴보았고, 다음과 같이 optimization이 진행된다.
1. discriminator update
-먼저 discriminator를 update한다.
1) Classifiy sampled images as fake
noise = make_noise(batch_size, latent_size, sample_scale)
fake_images = netG(noise, sample_scale)
logits = netD(fake_images)[:,0]
loss_fake_sampled = F.softplus(logits).mean()
2) Classify real exampleds as real
logits = netD(images)[:,0]
loss_real = F.softplus(-logits).mean() * options['discriminator_weight']
3) calculate P(D)
gp = calc_gradient_penalty(netD, images.data, fake_images.data)

(29. Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., Courville, A.: Improved training of wasserstein gans. arXiv preprint arXiv:1704.00028 (2017))
2. Generator Update
- 그 다음 generator를 update한다.
# Minimize fakeness of autoencoded images
fake_images = netG(netE(images, ac_scale), ac_scale)
logits = netD(fake_images)[:,0]
errG = -logits.mean() * options['generator_weight']
3. Autoencoder update
- reconstruction loss를 통해 auto encoder 및 generator를 update
netG.zero_grad()
netE.zero_grad()
reconstructed = netG(netE(images, ac_scale), ac_scale)
err_reconstruction = torch.mean(torch.abs(images - reconstructed)) * options['reconstruction_weight']
err_reconstruction.backward()
4. Classifier update
netC.zero_grad()
# Classify real examples into the correct K classes with hinge loss
classifier_logits = netC(images)
errC = F.softplus(classifier_logits * -labels).mean()
errC.backward()
log.collect('Classifier Loss', errC)
optimizerC.step()
논문에서는 실제 이미지와 유사한 openset example을 생성하는 것이 목적이기 때문에 다음과 같이 latent vector를
optimization한다.

이때, z* 를 만들때, openset example은 confidence가 낮다고 가정한다. 그래서 다음과 같이 objective를 설정한다.

이때 second term은 기존의 classifier logit에 unknown class logit을 추가하고, unknown class에 대한 score (logit)값을 0으로 잡은 term이다.
unknown class logit은 0으로 정의했기 때문에 사실상 아래의 첫 항처럼 표현 되서 1이 되는 것이고, 뒷 부분은 known class의 logit값들이다. 이때, 이 term을 minimize하면 known class에 대한 logit이 작아지고, 본 논문에서 정의한 것과 같이 confidence가 낮은 sample, 즉 open example이 생성된다.

이때 생성하는 과정은 다음과 같다.
1. 먼저 trainigset에서 random하게 하나의 image를 sample하여 encoder에 넣는다. ( z = E(x) )
2. 위의 optimization식을 이용해 z*를 만들어낸다.
3. 만들어낸 z*를 이용해 counter factual image를 생성한다. ( G(z*) )
4. 생성된 G(z*) image들을 이용해 K+1 class로 label하여 학습시킨다.
코드는 아래와 같다.
for i in range(max_iters):
z = to_torch(z_value, requires_grad=True)
z_0 = to_torch(z0_value)
logits = netC(netG(z, gan_scale))
augmented_logits = F.pad(logits, pad=(0,1))
cf_loss = F.nll_loss(F.log_softmax(augmented_logits, dim=1), target_label)
distance_loss = torch.sum(
(
z.mean(dim=-1).mean(dim=-1)
-
z_0.mean(dim=-1).mean(dim=-1)
) ** 2
) * distance_weight
total_loss = cf_loss + distance_loss
scores = F.softmax(augmented_logits, dim=1)
log.collect('Counterfactual loss', cf_loss)
log.collect('Distance Loss', distance_loss)
log.collect('Classification as {}'.format(target_class), scores[0][target_class])
log.print_every(n_sec=1)
dc_dz = autograd.grad(total_loss, z, total_loss)[0]
z = z - dc_dz * speed
z = clamp_to_unit_sphere(z, gan_scale)
# TODO: Workaround for Pytorch memory leak
# Convert back to numpy and destroy the computational graph
# See https://github.com/pytorch/pytorch/issues/4661
z_value = to_np(z)
del z
print(log)
z = to_torch(z_value)
-Technical Details of Compared Approaches
위의 과정을 자세히 설명하면 다음과 같다.
먼저 training set을 이용해 encoder, generator, discriminator를 학슶기킨다.
그 이후 학습된 모델들을 이용해서 openset example을 생성한다.
본 논문에서는 6400장의 exemple image를 생성한다.
이 image들을 통해서 K+1 classifier를 학습시키고,
이때 기존에 학습시켰던 K-classifier의 weight를 initial값으로 활용한다.
그리고 Openset metric은 다음과 같이 사용한다.

위 식의 의미는 다음과 같다.
open class로 정해진 확률 - closed class에 정해진 확률에서 가장 큰 값
이렇게 하면 closed class에 큰 값으로 확률이 mapping된 sample의 경우,
그 class에 속할 확률이 높기 때문에 Openset이라는 확률을 줄여주는 방식이다.
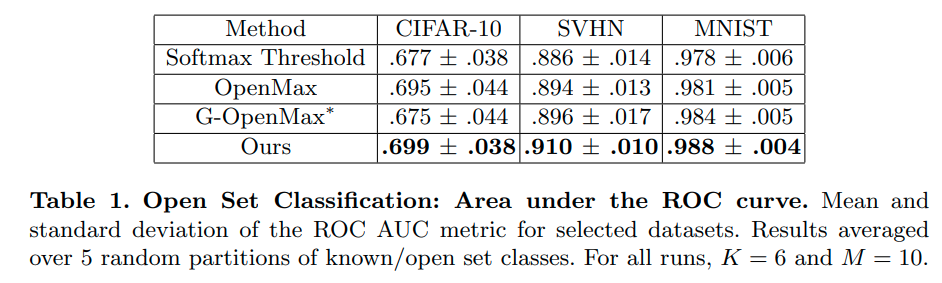
Results


- Opinion
Pros
기존의 G-openmax의 경우 DC-GAN을 이용해서 open example을 생성하지만,
본 논문 같은 경우에는 closed set과 유사한 sample을 생성하기 위해 추가적인 optimizaiton식을 사용하는 것이 특징이다.
또한 classifier에 open class를 추가하여 활용하기 때문에 좀 더 좋은 부분이 있다고 생각하긴 한다.
그러나 가장 최신 논문인 placeholder처럼 classifier를 embedding space의 중앙에 위치한다거나 하는 skill이 없기 때문에
성능은 높지 않다고 생각되어진다.
Cons
Open example을 생성할 때 결국 classifier의 confidence 값을 활용하는데, classifier의 현재 featrure extracting하는 능력을 기반으로 이를 판단하고 생성하게 된다. 결국 기존 classfiier가 openset으로 판단하는 능력을 좀더 interpolation하는 기능은 있지만 실제로 openset을 잘 걸러내는 방법이라고 보기는 어렵다고 생각한다. ( 좋은 openset example이라고 할 수 없다고 생각)
'Paper > Openset recogniton' 카테고리의 다른 글
| Adversarial Reciprocal Points Learning for Open Set Recognition : arXiv 2021 (0) | 2021.07.23 |
|---|---|
| Counterfactual Zero-Shot and Open-Set Visual Recognition: CVPR 2021 (0) | 2021.07.14 |
| Generative OpenMax for Multi-Class Open Set Classification : BMVC 2017 (0) | 2021.06.29 |
| Toward Open Set Deep Networks : CVPR 2016 (0) | 2021.06.28 |
| Learning Placeholders for Open-Set Recognition: CVPR 2021 Oral (0) | 2021.05.21 |