Paper
https://arxiv.org/abs/1511.06233
Towards Open Set Deep Networks
Deep networks have produced significant gains for various visual recognition problems, leading to high impact academic and commercial applications. Recent work in deep networks highlighted that it is easy to generate images that humans would never classify
arxiv.org
Code
https://github.com/abhijitbendale/OSDN
abhijitbendale/OSDN
Code and data for the research paper "Towards Open Set Deep Networks" A Bendale, T Boult, CVPR 2016 - abhijitbendale/OSDN
github.com
https://github.com/takumayagi/openmax-cifar10
takumayagi/openmax-cifar10
A simple training/evaluation code of open set recognition using OpenMax (https://arxiv.org/abs/1511.06233) - takumayagi/openmax-cifar10
github.com
출처 : 2020.02.21. HCAI Open Seminar
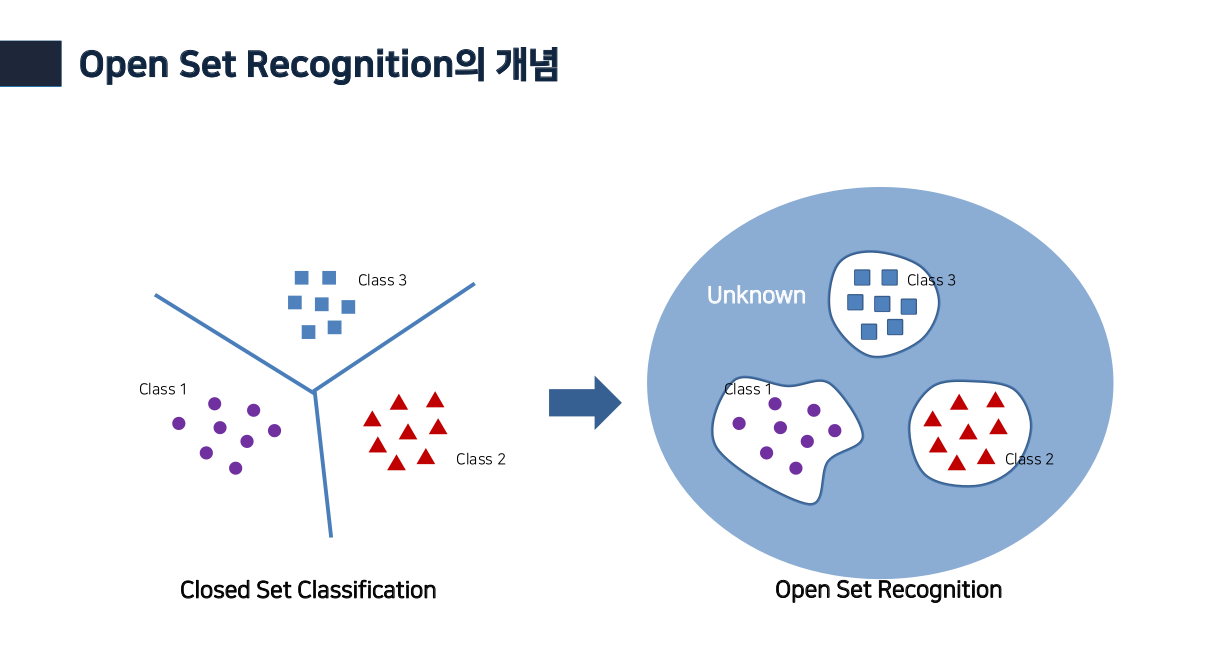
Open Set Recognition In Deep Networks 김상훈
Openmax의 기본 알고리즘은 다음과 같다.
- 기존 openset recognition은 softmax로 thresholding한다.
- 그러나 이러한 방식은 open class가 input으로 들어온다는 가정이 없는 상황에서의 사용하는 방법이기 때문에 성능이 낮다.
- openmax에서는 이러한 단점을 해결하기 위해서 input과 다른 class weight간의 거리를 측정하여 openset을 걸러낸다.
- 또한 openset에 대한 logit을 따로 두기 때문에 openset이 Input으로 들어온다는 가정 또한 들어가게 된다.
그림으로 표현하면 위와 같이 되며, 이를 거리 기반으로 openset을 걸러내는 방법이기 때문에 distance-based라고 볼 수 있다.

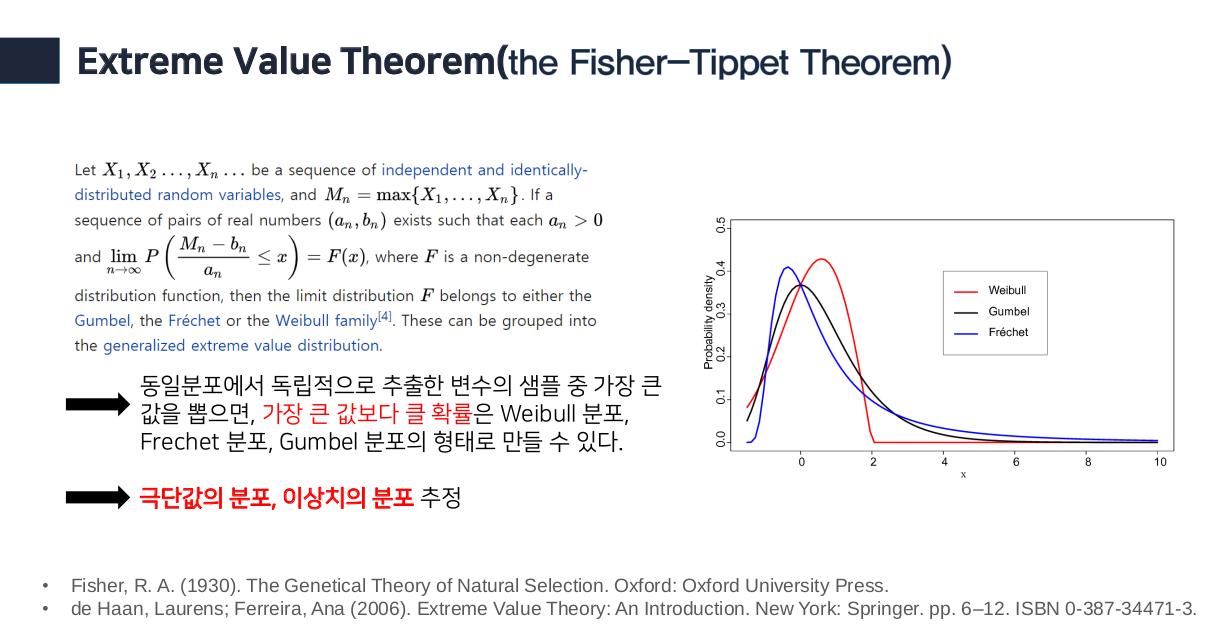
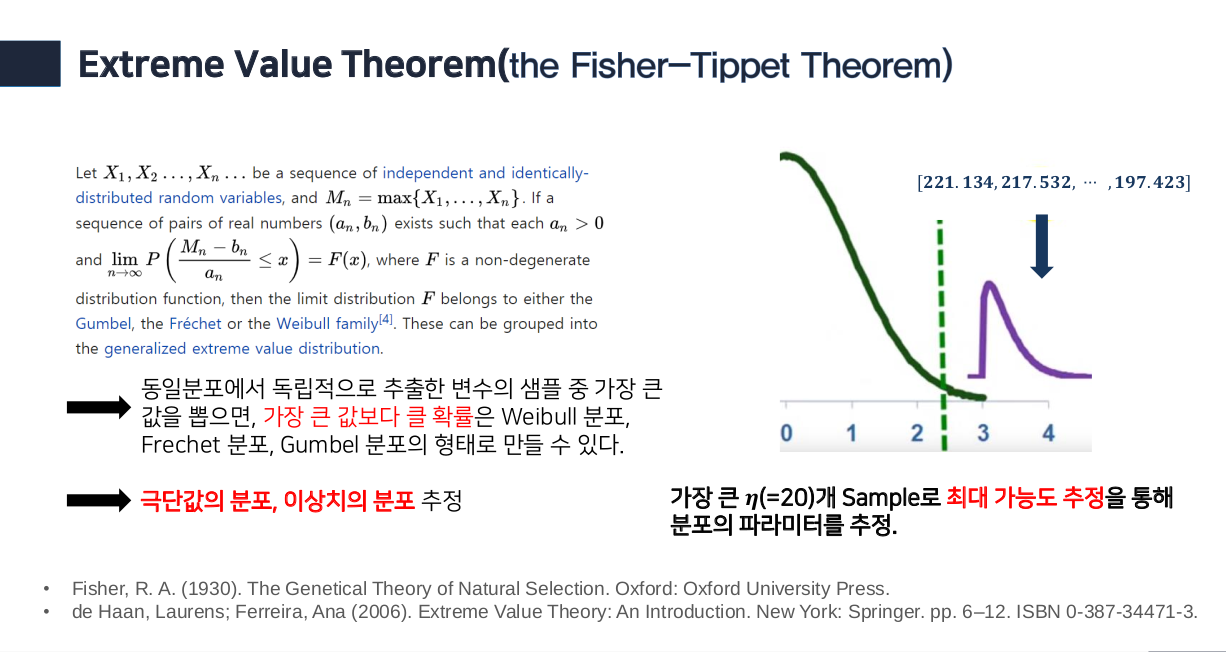
- 또한 openmax에서는 input으로 들어온 값이 이상치 (abnormal value)인지 확인하기 위해 Extreme Value Theorem을 적용하고 극단의 값, 이상치에 대한 분포인 Weibull 분포를 활용하여 이상치 여부를 판단한다.

-이와 같이 거리 기반, Webull분포를 활용하기 위해 사용하는 실제 알고리즘은 아래와 같다.
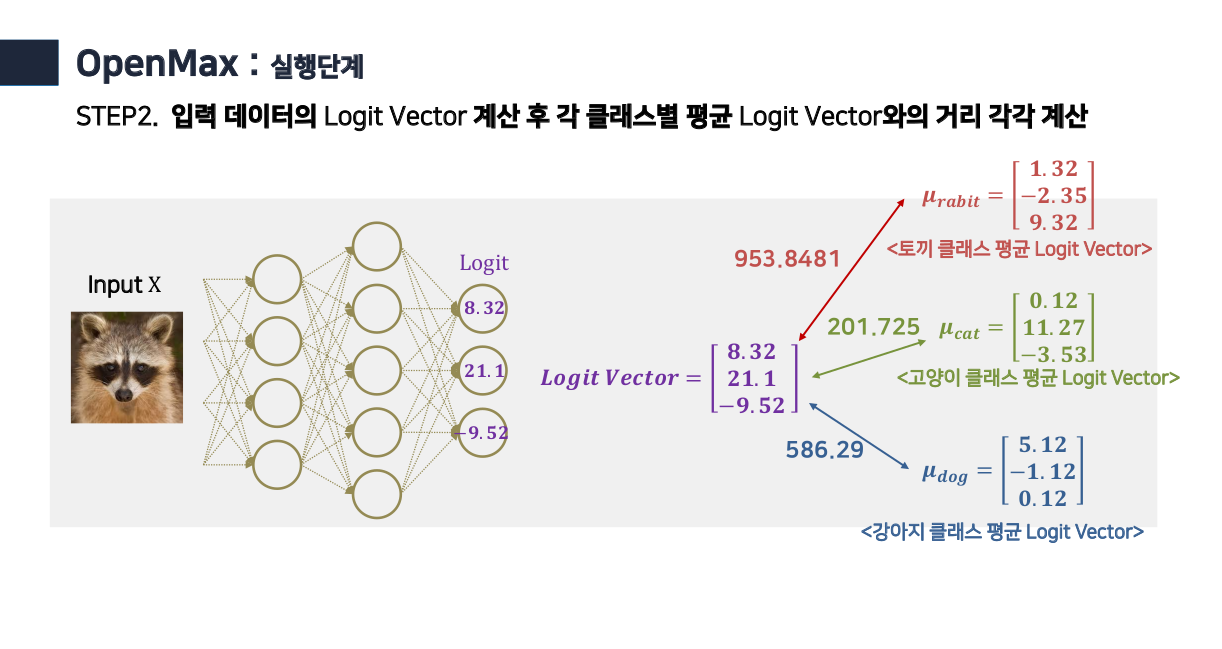
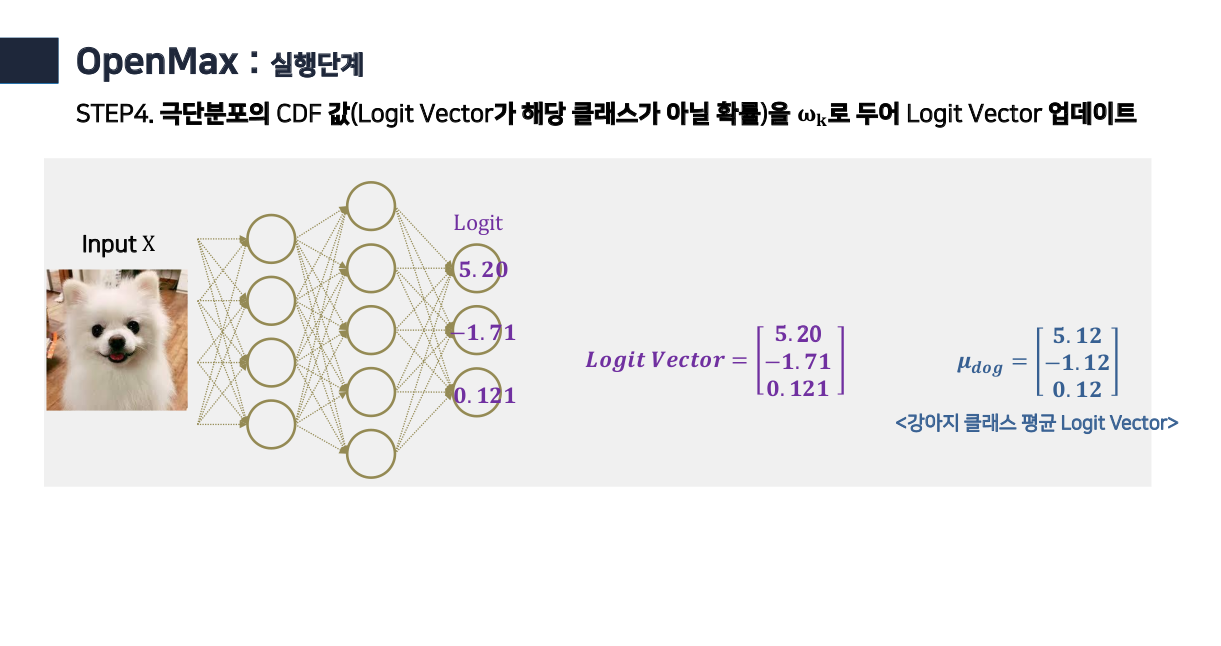
- 각 클래스의 weight (mean vector)와 거리를 구하기 위해 먼저 각 클래스 별로 mean vector 값을 구한다. (classifier weight값과 동일)

- 이 mean vector의 값과 각 트레이닝 셋의 class당 logit값간의 거리(distance) 값을 모두 구한다.
- 이는 distance값을 구하고 거리가 큰 값들을 추출하여 Weibull distribution에 fitting 시키기 위함이다.





- 이렇게 각 클래스 별로 이상치 값에 대한 분포, webull distribution이 준비가 되면 다음과 같이 하여 이상치를 탐지한다.





이렇게 하면 클래스에 대한 Weibull 분포에 맞춰서 확률이 도출된다. (각 클래스의 기준에 이상치일 확률들)

-이 확률을 기반으로 원래의 logit값을 조정하고, open class의 logit을 도출한다.

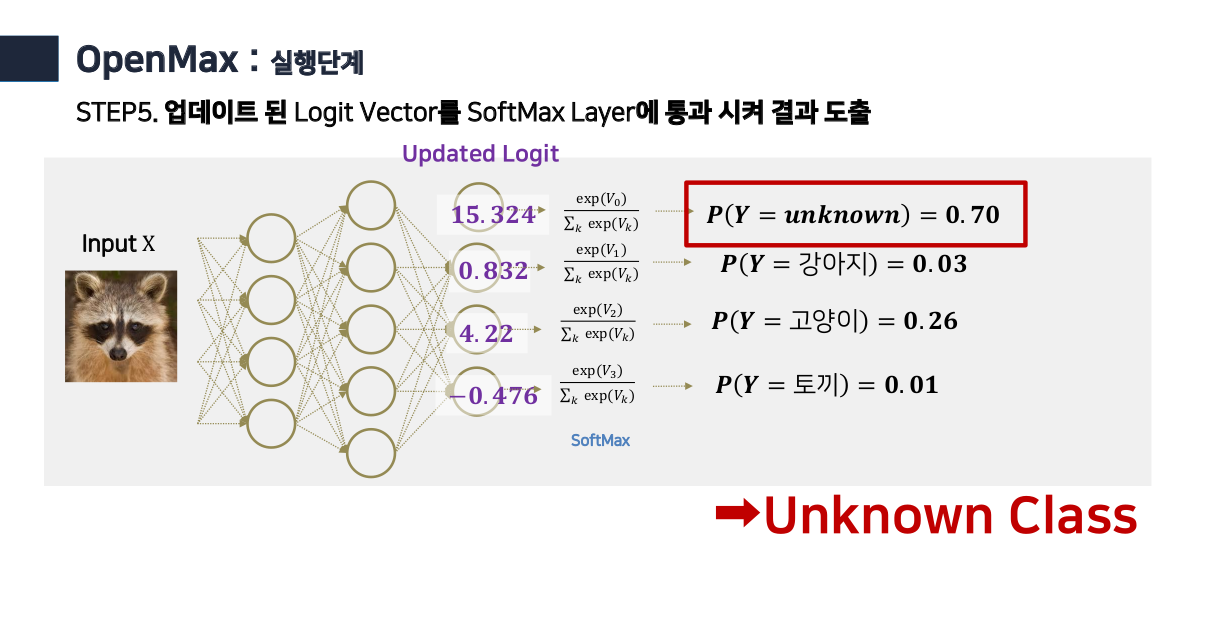
Open class가 아닌 경우는 다음과 같이 된다.







Pros
일단 거리기반으로 openset이 input으로 들어올 수 있다는 가정이 들어 갔다는 것이 큰 장점이다.
또한 Class 별로 logit에 대한 weibull distribution을 따로 두었기 때문에 class별로 threshold값이 지정되는 효과도 어느정도 있다고 본다. 그러나 결국에는 모든 Class에 대한 결과를 합쳐서 고려하기 때문에 이러한 효과는 희석되는 듯하다. (정확히는 모르겠음)
Cons
거리기반으로 openset input에 대한 대비를 하기는 했지만, 기타 다른 논문들 처럼 open example을 활용한다던가, 기존 training class를 좀 더 뭉치게 만든다던가 하는 방법이 없기 때문에, 다른 논문들에 비해 성능이 낮다는 단점이 있다. 옛날 논문이기 때문에 어느정도 고려를 해주어야 하는 듯 하다.