Paper
https://arxiv.org/abs/2103.00887
Counterfactual Zero-Shot and Open-Set Visual Recognition
We present a novel counterfactual framework for both Zero-Shot Learning (ZSL) and Open-Set Recognition (OSR), whose common challenge is generalizing to the unseen-classes by only training on the seen-classes. Our idea stems from the observation that the ge
arxiv.org
Code
https://github.com/yue-zhongqi/gcm-cf
yue-zhongqi/gcm-cf
[CVPR 2021] Released code for Counterfactual Zero-Shot and Open-Set Visual Recognition - yue-zhongqi/gcm-cf
github.com
Abstract
본 논문에서는 Zero-Shot Learning과 Open-Set Recongniton에 대해 새로운 framework를 제안하였다. (counterfactual framework) 이 2가지 문제는 모두 training때 보지 못한 unseen data에 대해서 모델이 generalized (seen data, unseen data 모두 잘하는) 능력을 갖추는 것이 핵심인 문제이다.
2가지 문제 모두다 unseen data를 다루는 문제이기 때문에 unseen data를 생성하는 방법을 많이 사용한다.
그러나 기존의 방법들은 unseen data가 실제 unseen data의 distribution과 다른 distribution이 생성된다는 문제점이 있었다.
이러한 이유를 본 논문에서는 생성된 샘플이 'Not Counterfactual Faithful'하기 때문이라고 설명하고 있다.
때문에 본 논문에서는 Counterfactual Faithful한 sample을 생성하여 원래 unseen data의 distributuion과 동일함 distribution을 샘플을 생성하는 것을 시도한다.
Counterfactual faithful한 것의 의미는 다음과 같다.
"만약 특정 sample의 attribute는 유지한채 class에 대한 attribute만 변화하면 어떠한 sample이 만들어지는가?"
(완전히 무의미한 sample이 아닌 실제 존재하는 attribute 및 feature를 유지한채 sample을 생성한다는 의미인듯)
이러한 방법으로 faithfulness를 확보하면 'Consistency Rule'를 unseen/seen binary classification에 적용할 수 있다.
예를 들면 다음과 같이 수행가능하다. 생성된 counterfactual sample이 특정 class에서 나온것이냐? 라는 물음에 binary classsification 형태로 yes or no를 도출가능하다.
Introduction
기존의 ZSL (Zero-Shot Learning) 이나 OSR (Open-Set Recongniton) 방법들은 기존 training dataset의 sample들을 이용해서 unseen dataset에 대한 sample을 생성하고 이를 이용해서 test time때 unseen class를 구분하는 알고리즘을 주로 사용했다. 그러나 이와 같은 방법은 생성된 unseen class에 대한 sample들이 실제 unseen class의 sample들과 다른 distribution을 가진다는 문제점이 존재한다. 아래 그림 (a)를 보자.

그림을 보면 생성된 unseen class와 True unseen class sample에 대한 차이가 존재하기 때문에 decision boundary가 불균형하게 형성되고 따라서 test때 true unseen class sample을 잘구분하지 못하는 것을 확인할 수 있다. 저자는 이러한 현상이 모든 ZSL 알고리즘에서 나타났다고 말한다. (Seen class에 대한 recall 값이 높음)
(이와 같은 일이 openset 에서도 맞는 말인지는 생각해 봐야 한다. OOD 논문에서 GAN으로 생성한 sample을 openset으로 활용하는 경우 생성된 sample이 True seen class sample에 True unseen class sample보다 더 가까워야 되는 것이 아닌가 생각해본다.)
이러한 문제는 사실 feature의 disentanglement문제와 관련이 있다고 저자는 말한다. 만약 feature을 disentangle할 수 있다면, 생성하는 unseen class data를 more sensible하게 생성할 수 있을거라고 이야기한다. 그러나, feature를 disentanglement하는 일을 어려운 일이며, 적절한 supervision이 필요한 일이다.
때문에 저자는 feature를 disentanglement하는 방법 대신 다른 방법을 제안하는데, 바로 Counterfactual Inference를 제안한다. (https://badlec.tistory.com/262?category=1035281)
X를 sample을 나타내는 Random variable, 이 sample을 encoding한 결과를 Z = z(X=x), (feature, attribute) , 그리고 class정보를 vector로 나타낸 것을 Y = y(X=x)라고 하면 sample x에 대한 counterfactual sample x_var는 다음과 같다.
만약 feature가 Z = z ( X = x ) 일때, Y가 특정 y Class라고 가정을 하면, X는 x_var가 될것이다.
즉, 어떤 feature가 있을 때, class에 대한 정보, vector만 바꾸어 주면 어떤 sample이 생성되는지 보고,
그 생성된 sample을 counterfactual이라고 본다.
이렇게 생성하는 경우 기존의 방법과 다른 점이 있다.
바로 기존 방법의 경우, sample-agnostic ( 부자연스러운 sample을 생성) 한다는 것이고, (gaussian noise z 기반으로 생성하기 때문.. 이라고 논문에서는 설명) 저자의 방법은 sample-specific한 방법이라고 설명하고 있다. ( sample을 feature, z(x)를 기반으로 생성하기 때문임.)
저자는 이러한 방식의 정당성을 부여하기 위해서 아무것도 없는 상태에서 unseen class sample을 생성하는 것보다, 특정 attribute, observed fact Z=z(x)를 기반으로 생성하는 것이 생성할 때, 잃어버리는(lost) feature, attribute없이 생성이 가능하다고 설명하고 있다. (마치 인간이 화석으로 부터 공룡의 모습을 상상하는 것 처럼..)
그리고 class attrribute Y와 class sample Z를 disentangle함으로 Counterfactual Faithfulness를 만족할 수 있다고 한다. 그리고 이를 만족하면 위 그림에서 (c) 부분과 같이 True sample unseen class와 유사한 distribution을 가지는 unseen class sample을 생성할 수 있다고 한다.
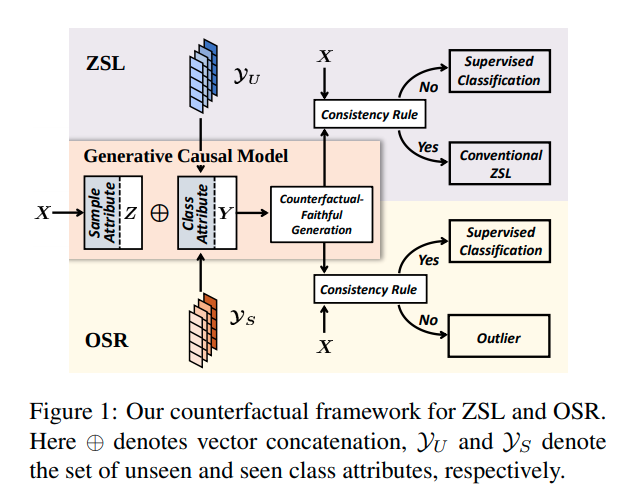
위와 같은 논리로 본 논문에서 제안한 counterfactual framework는 위와 같다. X sample이 input으로 들어오면 feature Z(Sample attribute)를 추출하고, Class Attribute Y와 concat을 한다. (정보를 더해줌) 이렇게 만들어진 최종 feature, attribute를 이용해서 sample을 생성한다. 이때 생성된 sample과 원래 sample X와 비교하는 과정을 거치게 된다. (Consistency Rule 적용) 이때 원래 Sample과 유사하면, 기존에 봤던 Class라고 판단하고, 다르면 처음보는 Class라고 판단한다. (Yes, No 부분)
Method
논문에서 어찌되었던 Counterfactual 논리를 사용하고 있기 때문에, 자신들의 Causal Model을 소개하고 있다. 논문에서는 Generative Causal model이라고 소개하고 있으며, 다음과 같이 도식화해서 표현한다.
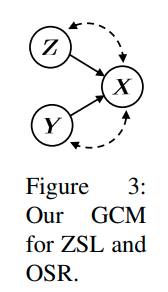
도식에 대한 자세한 설명은 논문을 참고하면 된다. 그러나 크게 중요하다고는 생각안한다.
openset recognition에 대한 알고리즘만 좀 더 살펴보겠다.
기존의 method는 다음과 같은 알고리즘에 따라 openset을 구분하였다.
1. 먼저 test sample x가 input으로 들어오면 모델의 파라메터를 기반으로 test sample에 대한 class를 예측하게 한다.
2. 이 class정보를 이용해서 Pθ(X|Z = z, Y = y)로 부터 sample x'을 생성한다.
3. 이렇게 생성한 x'이 원래 sample x와 유사하면 known, 안유사하면 unknown처리한다.
그러나 이러한 method의 경우 z가 보통 gaussian noise가 사용되고, 즉 , sample-specific한 sample이 생성되지 않는다.
이러한 경우 condition으로 주어지는 y가 entangle되어 있기 때문에 (여러 sample들의 정보를 함께 담고 있음)
실제로 생성되는 이미지도 sample들의 feature가 entangle(여러 sample, instance 정보들이 섞어있음)되어 생성되게 되고, 이는 실제의 class sample distribution과 다른 분포를 낳는 결과를 도출한다.
이와 다르게 본 논문에서는 Counterfactual sample을 생성하며 다음과 같은 과정을 거친다
1. feature extraction
먼저 “given the fact that Z = z(x)” 를 구하기 위해서 x sample에 대한 attribute z를 추출한다.
이는 다음과 같이 표현할 수 있다. z(x) ∼ Qφ(Z|X = x)
2. apply intervention target y
그 다음 “had Y been y”를 구한다. 기존 방법의 경우 classification model에 x sample을 넣고 예측하는 class y를
사용했지만, 본 논문에서는 intervention target Y=y를 사용한다. (특정 class를 임의로 지정해줌)
3. Prediction
마지막으로 -“X would be x˜” 를 구한다. 방법은 x를 encoding한 Z , (Z = z(x) (fact))와 intervention target Y ( Y = y (counterfact) ) 로부터 sample x˜를 생성한다. ( Pθ(X|Z = z(x), Y = y) )
이렇게 만드는 경우, 기존 방법은 클래스 정보만 있는 상황에서 noize기반으로 생성하였기 때문에 sample간의 feature가 entangle되어있는 sample이 생성되었다면, 이 경우, 특정 sample을 encoding한 정보를 함께 주는 상황에서 생성하기 때문에, 해당 class정보에서 해당 sample에 해당되는 feature만 disentangle하여 sample을 생성한다는 장점이 있다.
이렇게 생성한 sample이 우리는 true unseen class distribution에 속하길 바라는 것이다.
그래서 기존 방법과 비교한 그림이 다음과 같다.

Inference in OSR
OSR에서는 다음과 같이 위의 방법을 활용한다. Counterfactual sample을 기존 y에 대해서 (intervention y) 생성하고,
이때, unknown sample과 distance를 계산해 일정 threshold보다 넘으면 openset으로 분류한다.
이때 자세한 과정은 다음과 같다.
test sample x 와 counterfactual samples x~간의 Euclidean distance를 모두 계산한 다음, 그 중에서 가장 작은 distance를 기준값으로 활용한다. 이때 d_min이 특정 threshold를 넘으면 unseen으로 분류한다.

Counterfactual-Faithful Training
위의 method는 모두 counterfactual-faithful 조건이 만족되야 한다는 것이 중요하다.
그리고 counterfactual-faithful은 다음 조건이 만족되면, 성립하게 된다.
Theorem. The counterfactual generation Xy[z(x)] is faithful if and only if the sample attribute Z and class attribute Y are group disentangled.
(sample attribute Z와 class attribute Y가 disentangle이 되는 경우, couterfactual generation은 faithful하다고 말할 수 있다.)
(증명은 아래 논문 Appendix에 있다, )
https://arxiv.org/abs/1812.03253
Counterfactuals uncover the modular structure of deep generative models
Deep generative models can emulate the perceptual properties of complex image datasets, providing a latent representation of the data. However, manipulating such representation to perform meaningful and controllable transformations in the data space remain
arxiv.org
다음 그림은 이러한 disentanglement가 잘 되었을 때와 안되었을 때를 구분하여 나타낸 그림이다.

이러한 disentanglement는 fully하게 하는 것은 불가능에 가깝다.
https://arxiv.org/abs/1811.12359
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
The key idea behind the unsupervised learning of disentangled representations is that real-world data is generated by a few explanatory factors of variation which can be recovered by unsupervised learning algorithms. In this paper, we provide a sober look
arxiv.org
그래서 appoximation하여 disentanglement를 시도하게 되는데, 다음과 같은 objective를 활용하게 된다.

모든 Loss는 disentanglement를 위함이다.
1) L_z : Disentangling Z from Y
- B-VAE Loss (L_z)를 일단 minimize한다.
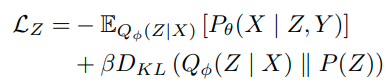
- disentanglement 분야를 잘몰라서 정확히는 모르겠지만 B값을 조정하여 Z를 Y distribution에 영향을 받지 않도록 objectieve를 줄 수 있다고 한다. (논문 참고)
2) L_y : Disentangling Y from Z
위의 Loss만으로는 disentangle이 충분하지 않다고 하고, L_y Loss를 추가한다. 이유는 논문에서는 최근 over-parameterized model의 경우 Y없이 noise Z 만으로 sample을 생성하는 경우가 있고, 이는 생성된 sample이 non-faithful한 것으로 leadinig이 가능하다고 한다. 어찌되었든 disentangle term을 더 넣어야 된다.
사용하는 term은 다음과 같이 contrastive loss term을 적용한다.
원래 sample x와 그 sample을 encoding한 후 원래 class를 기반으로 그대로 생성한 sample x_y간의 거리는 가깝게 한다.
그러나 원래 sample x와 다른 class를 intervention하여 생성한 x'과의 거리를 멀게 만든다.

이때 사용하는 dist는 Euclidean distance이다.
이는 똑같은 encoding Z로 부터 class Y에 대해서 intervene되기 전과 후의 차이를 크게 만드는 것이기 때문에 disentanglement에 더욱 도움을 주게 된다.
3) L_F : Further Disentangling by Faithfulness
잘모르겠지만.. VAE의 lower bound를 더 loose하게 하면 더욱 faithfulness를 증가할 수 있다고 한다.
그리고 이를 위해 WGAN을 사용한다. discriminator를 사용해서 원본 x에 대해서는 1에 가까운 값,
생성된 x'에는 0에 가까운 값을 출력하도록 한다.
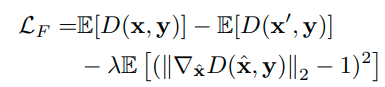
Experiments
[Implementation detail]
OSR에서 사용된 네트워크는 CGDL에서 사용된 네트워크를 본 논문에서도 사용하였다. (Ladder-VAE)
X는 실제 이미지가 사용된다. openset을 구분하는 방법은 reconstuction error가 사용된다.
result는 F1-score로 측정이 되었다.
CGDL밖에 비교를 안했는데, 자신의 disentanglement 기법이 효과가 있음을 알려주는데, 힘을 쏟았다고 생각한다.

또한 Openness가 커져도 본 논문의 method인 GCM-CF는 강건함을 볼 수 있다.


Summary
- 본 논문은 기존의 ZSL과 OSR 방법에서 주로 사용하는 unseen class에 대한 생성 방법론에 대해 문제점을 제기하고, developed된 unseen class sample을 생성하는 방법을 제시한 논문이다. 기존의 gan 기반 unseen class 생성 방법은 sample간의 feature (attribute) entanglement 현상이 있어 실제로 생성했을 때, true unseen class distribution과 다른 것을 확인할 수 있었다. (seen class에 대한 recall 값이 높은 것으로 간접적으로 증명) 이때, true unseen class distribution에 맞는 sample을 생성하기 위해서 counterfatual faithfulness라는 개념을 가지고 온다. 이는 ICLR 2020 논문에서 수학적으로 증명한 내용인데, 만약 sample을 생성할 때, 생성할 때, 기반이 되는 정보인 Z( feature, attribute), 와 Y (class)가 disentanglement된 다음 제공되면 생성되는 sample이 counterfactual faithfulness, 즉 true unseen class distribution과 유사하다는 것이 보장된다는 것이다.
그래서 이를 기반으로 unseen class sample을 생성하게 되고, 이러한 방법은 기존의 unseen class sample을 생성하는 것 보다 더 정확하게 생성이 가능하기 때문에, 더 좋은 성능을 보였다는 내용의 논문이다.
Pros
문제제기가 잘된 논문이라고 생각한다. 기존 생성모델 기반으로 OSR 문제를 푸는 방식에서 부족한 부분을 잘지적했다고 생각한다. 생성모델의 disentanglement 문제에 대해 잘이해했기 때문에 쓸 수 있는 논문이라고 생각한다.
Cons
다른 OSR 논문들과의 비교가 부족하다고 생각한다. split도 다른 듯 하다. 하지만 논문자체가 OSR이 중심이 아니라 기존의 생성 방법에서 문제점이 있다는 것을 잘지적하고 그에 대해 해결법을 잘제시한 논문이라 다른 method와의 비교가 부족하지만 논문이 되었다고 생각한다.
'Paper > Openset recogniton' 카테고리의 다른 글
| Adversarial Reciprocal Points Learning for Open Set Recognition : arXiv 2021 (0) | 2021.07.23 |
|---|---|
| Open Set Learning with Counterfactual Images : ECCV 2018 (0) | 2021.07.07 |
| Generative OpenMax for Multi-Class Open Set Classification : BMVC 2017 (0) | 2021.06.29 |
| Toward Open Set Deep Networks : CVPR 2016 (0) | 2021.06.28 |
| Learning Placeholders for Open-Set Recognition: CVPR 2021 Oral (0) | 2021.05.21 |