Paper
Rethinking the Value of Labels for Improving Class-Imbalanced Learning
Real-world data often exhibits long-tailed distributions with heavy class imbalance, posing great challenges for deep recognition models. We identify a persisting dilemma on the value of labels in the context of imbalanced learning: on the one hand, superv
arxiv.org
Code
github.com/YyzHarry/imbalanced-semi-self
YyzHarry/imbalanced-semi-self
[NeurIPS 2020] Semi-Supervision (Unlabeled Data) & Self-Supervision Improve Class-Imbalanced / Long-Tailed Learning - YyzHarry/imbalanced-semi-self
github.com
Introduction
일반적인 supervised learning에서는 data의 label은 무조건 도움이 된다.
unsupervised learning과 비교해보면 그것을 알 것이다.
그러나 imbalanced learning에서는 상황이 달라진다.
majority class에 의해 decision boudary가 강하게 형성되게 되고,
아래와 같이 decision boudary가 형성되는 경향성을 보이게 된다.

그래서 다음과 같은 의문을 제기 한다.

그래서 본 논문에서는 imblanced learning에서의 label의 positive한 면과 negative한 면을 살펴보고 이를 semi-supervised learning과 self-supervised learning 방식으로 이용하여 sota를 달성했다.
먼저 positive view는 imbalanced label이 유용하다는 것이다. 그래서 extra unlabeled data를 추가적으로 사용하여 psedo-labeling data를 형성하고 이를 통해 semi-supervised 방식으로 추가적인 학습을 진행하면, imblanced data 학습을 통한 성능이 향상된다는 것을 증명하고 있다.
그리고 negative view는 imbalanced label이 항상 유용하지는 않다는 것이다. imbalanced label만을 이용해 학습할 경우 acc의 최대치의 bound가 정해지게 된다. 그러나 label을 따로 지정하지 않는 self-supervised 방식을 적용하면 imbalanced label만을 이용해 학습할 경우 제한되는 acc의 한계를 넘을 수 있다는 것이다. 본 논문에서는 이를 수식 및 실험적으로 증명하고 있다.
Imbalanced Learning with Unlabeled Data
먼저 Unlabel Data를 추가적으로 학습에 사용할 때, 어떠한 효과가 있는지 알아보기 위해 이론적으로 살펴본다.
먼저 binary classification 문제를 고려한다. data는 2개의 Gausssian의 mixture P_xy 모델을 사용한다.
label Y는 positive value (+1) , negative value (-1) 2가지를 같은 확률 (0.5)의 확률로 가지게 된다.
그래서 Y=+1 일때, data X의 label이 +1 인 경우는 다음과 같이 normal distribution을 따른다. ( label 1에 대한 u_1 gaussian)
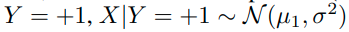
Y= -1 일때, data X의 label이 -1 인 경우는 다음과 같이 normal distribution을 따른다. ( label 2에 대한 u_2 gaussian)

이 경우 optimal bayes's classifier는
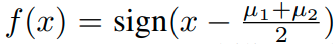
가 된다.
이 경우,

가 된다.
이러한 상황에서 base classifier f_b를 정의해보자. (which is trained on imbalanced training data)
그리고 extra unlabeled data

가 주어졌다고 생각해보자.
base classifer f_B를 이용해 unlabeled data에 대해서 psuedo-label을 형성한다.
결과적으로 psuedo-label이 +1인 unlabeled-data set을

psuedo-label이 -1인 unlabeled -dataset을
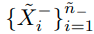
로 표시한다.
이때, psuedo-label이 +1로 분류된 data가 실제로 label이 +1인 경우 indicator를 사용해 '1'로 표시해준다.

그래서,

이때

가 되고, 의미는 f_B가 Positive class에 대하여 p의 acc를 가진다는 의미이다.
유사하게
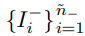


가 되고, 의미는 f_B가 Negative class에 대하여 q의 acc를 가진다는 의미이다.
결과적으로

로 정의가능하다.
이러한 상황에서, extra unlabeled data를 이용해,
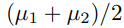
를 배우는 것이 목표이다.
저 parameter를 측정하는 방법은 아래와 같이 측정이 가능하다.

이때 다음과 같은 결과를 얻을 수 있다.
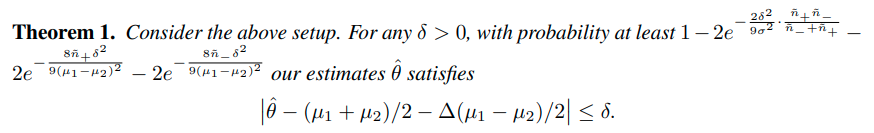
이 결과는 다음과 같이 해석할 수 있다.
1) Training data imabalance를 estimation의 정확도에 영향을 준다.
위 수식을 보면 △ 가 estimation에 영향을 주는 것을 확인 할 수 있다. 즉, imbalance 정도가 estimation에 영향을 준다.
2) unlabeled data의 imbalanced 정도는 good estimation을 얻을 확률에 영향을 준다.
이때, unlabeled data가 balanced인 경우 good estimation을 확률이 증가한다.
그러나 unlabeled data가 balanced하지 않더라도 어찌되었든 imbalanced data를 추론하는 것에는 도움이 된다.
Semi-Supervised Imbalanced Learning Framework
이러한 가설을 기반으로 본 논문에서는 "Semi-Supervised Imbalanced Learning Framework"를 제안한다.
먼저 original imbalanced dataset 으로 부터 학습시킨 intermediate classifier 'f' 를 얻는다.
그리고 이 'f'를 이용하여 unlabeled data D_u로 부터 pseudo-label y를 생성한다.
이를 이용하여 최종 모델 f는 다음과 같은 Loss식을 이용해 얻는다.

여기서 w는 unlabels weight이다.
이 방식은 다른 어떠한 SSL 방식에도 적용이 가능하기 때문에 더욱 실용적이다.
Experimental Setup
실험은 2가지 dataset에서 진행되었다.
CIFAR-10, SVHN
CIFAR-10의 경우 CIFAR-10에 유사한 Tiny-imagenet class data를 unlabel data로 사용한다.
SVHN의 경우 extra SVHN dataset을 unlabeled dataset으로 사용한다.
Why good?
이건 SSL을 좀 더 이해해야 될듯
Experiment results

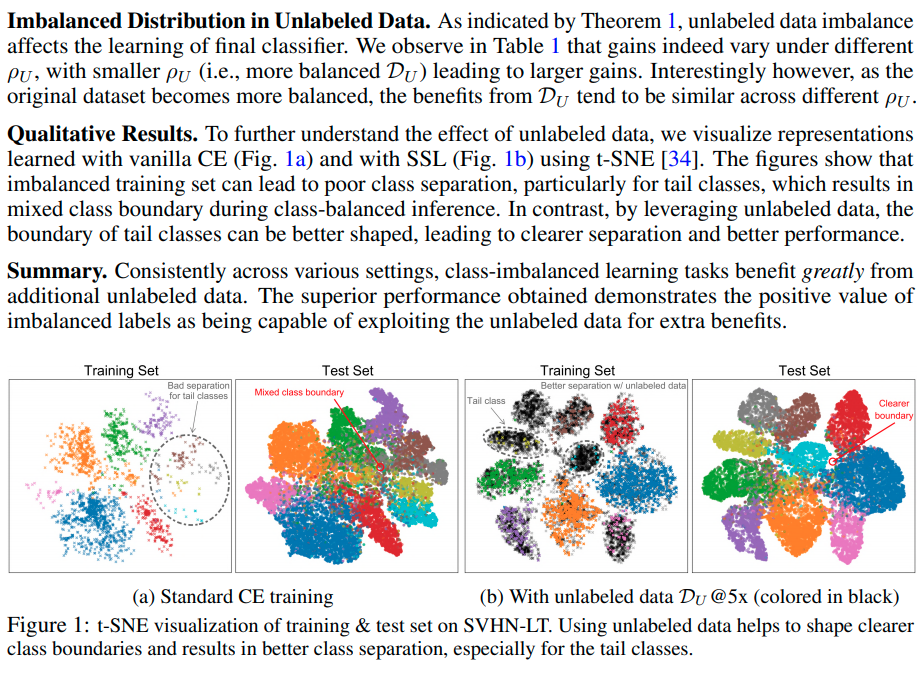
A Closer Look at Unlabeled Data under Class Imbalance
이러한 SSL 방식을 통해 unlabel data를 이용하는 방법은 unlabel data와 original data의 distribution match가 잘맞는 것이 중요하다.

- Data relevance가 낮으면 성능에 저해가 된다. 기준은 Relevance ratio 60% 이다.
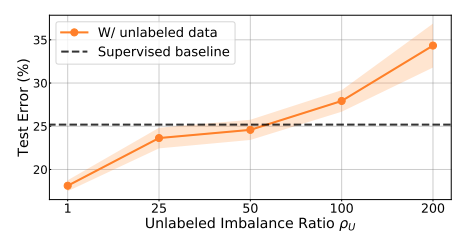
Imbalanced Learning from Self-Supervision
Imbalaced data의 label은 어찌되었든 bias를 가지고 있기 때문에 classification 성능에 악영향을 끼치게 된다.
따라서 본 논문에서는 label을 따로 지정하지 않는 self-supervision 방식을 도입하여 성능 향상이 가능함을 보여준다.
먼저 이론적으로 self supervision이 도움이 되는 것을 증명하기 위해 다음과 같은 상황을 가정한다.
d-dimension binary classification, data distribution P_xy mixture Gaussian을 가정한다.
이때, Y=+1은 prob p_+ 를 가지고, Y=-1은 prob p_-를 가진다. (p_- = 1-p_+) 그리고 p_-는 0.5보다 큰 것을 가정한다.
(major class를 negative로 정의하기 때문임)
Y= +1, X는 d-dimensional isotropic Gaussian이라고 정의할 경우,



이유는 negative sample이 더 큰 variance를 갖기 때문이다.
(majority class는 sample수가 많고 그 이유 때문에 큰 variance를 갖는다.)
이 상황에서 self-supervision을 적용하기 전과 적용한 후를 비교하기 위해 linear classifier에 self-supervision을 적용하기 전과 후를 비교할 예정이다.
linear classifier를

여기서 'feature'는 standard training을 통해 배우는 feature이다.
self-supervised learning을 통해 배우는 feature는 다음과 같이 표현한다.
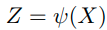
이때 다음과 같은 결과를 도출할 수 있다.
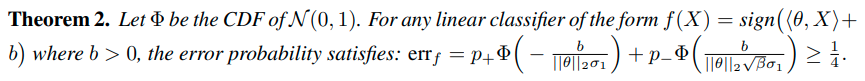
Theorem 2는 standard training으로는 3/4이상의 acc를 가지지 못한다는 것을 이야기 한다. (B가 3일때)
그러나 self-supervision을 통해 Z를 추출하면 더 높은 정확도를 얻을 수 있다.


위의 내용은 다음과 같은 내용을 의미한다.
처음에 imbalanced dataset의 label을 제거한 후, self-supervised 방법을 통해 f_ss 를 만든 후 imblanced learning을 하는 경우 더 좋은 성능을 보이게 된다.
Self-Supervised Imbalanced Learning Framework
SSP 를 적용하는 방식은 다음과 같다. 먼저 self-supervision 방식을 통해 f를 학습시킨 후, standard training 방식을 적용하여 final model을 만든다. 이러한 방식은 어떠한 imbalanced learning method에 적용이 가능하기 때문에 장점이 있다.
Experimental Setup
RotNet이랑 MoCo를 사용함.
학습은 pretrain, standard train 모두 같은 epoch 적용 (CIFAR-LT 200 epoch , ImageNet-LT 90 epoch)
results

