Paper
M2m: Imbalanced Classification via Major-to-minor Translation
In most real-world scenarios, labeled training datasets are highly class-imbalanced, where deep neural networks suffer from generalizing to a balanced testing criterion. In this paper, we explore a novel yet simple way to alleviate this issue by augmenting
arxiv.org
Code
alinlab/M2m
Code for the paper "M2m: Imbalanced Classification via Major-to-minor Translation" (CVPR 2020) - alinlab/M2m
github.com
Introduction
Imbalanced data를 다루는 방법에는 여러가지 방법이 있지만 그중에서 re-sampling 방법이 있다.
re-sampling 방법은 minority class의 sample을 생성하여, minority class의 수가 부족한 것을 해결하는 방법이다.
대표적인 re-sampling 방법으로는 SMOTE가 있다.
SMOTE는 minority class의 sampling이 feature space상에 embedding되면 sample들의 linear combination을 하여
새로운 feature space상에 sample들을 생성하는 방법이다.
그러나 minority class의 sample이 아주 작은 경우 sample을 생성하더라도 다양한 sample이 생성되지 않기 때문에,
poor performance를 보여주는 경우가 많다.
Contribution
본 논문에서는 minority sample을 생성하는 새로운 방법을 제시한다. : Major-to-minor Translation (M2m)
기존 SMOTE 계열 방법들은 minority sample을 추가로 생성하기 위해서 minorrity class의 sample들을 이용했다.
그러나 본 논문에서는 minority sample을 생성하기 위해 majority sample을 이용한다.
M2m: Major-to-minor translation
data imbalanced 문제는 보통 다음과 같이 귀결된다.
일반적인 classification 문제는 train data distribution과 test data distribution이 동일하다고 가정한다.
그러나 imbalnced data 문제는 train data distribution과 test data distribution이 동일하지 않다.
train data 의 경우 highly imbalanced , test data의 경우 uniform distribution을 가진다.
그래서 imbalanced된 train data를 학습하여, uniform인 test data에 잘 동작하는 것이 목표이다.
M2m method의 경우, 이를 행하기 위해 sythetic sample을 majority class로 부터 생성하여 minority sample에 추가한다.
이러한 방법에는 image to image translation을 통한 minority image를 생성하는 방법도 존재하겠지만,
추가적인 학습 및 복잡한 방법론이다.
본 논문에서는 majority sample을 target minority sample에 대한 confidence를 maximize하는 형태로
새롭게 minority sample을 생성한다.
이때 another baseline classifier g를 사용하는데, 이는 기존의 imblanced training data에 대해 standard ERM training을 통해 학습한 classifier이다.
때문에 classifier g는 minority class에 overfitting되어 있으며, balanced test dataset에는 generalize가 잘 되어있지는 않은 classifier이다.
이때 우리는 g를 이용해서 minority sample을 생성할 것이다. 그러므로 g는 majority class의 sample들을 이용해 minority sample들을 잘 생성할 수 있다고 가정한다.
그리고 생성된 sample들을 이용해 classifier f를 balanced testing criterion에 맞추어 새로 학습한다.
이때 g를 이용해 sample을 생성할 때, 사용하는 optimization problem 수식은 다음과 같다.
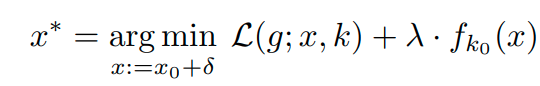
이때, L은 cross entropy loss이고, λ는 hyper parameter이다.
본 식의 의미는 다음과 같다.
major class의 sample x_0에다가 noise δ를 더해서 minority class sample x를 생성하는데,
이때, g classifier에 input으로 넣어서 target minority class k 에 대한 loss가 최소가 되도록 한다.
그리고 생성된 sample x^*를 f classifier를 학습시키는 데 이용한다.
이때, 생성된 sample의 경우 f classifier에서 기존 class인 k_0로 분류되지 않도록 regularization term을 넣어준다.
이렇게 하는 경우, x_0에서 생성된 sample x가 f_classifier에서 기존 class인 k_0로 분류되는 것은 막으면서
x_0의 주요한 feature는 남길 수 있다고 저자는 말하고 있다.
(f_classifier에서도 k_class로 바로 prediction하도록 optimization 수식을 세우면, 주요한 feature가 사라질 가능성 있음)
그림으로 나타내면 아래와 같다.

Underlying intuition on M2m
결론적으로 M2m은 다음 논문에서 제시한 방법을 이용한다.
-> Adversarial examples are not bugs, they are features.
결국 majority class에서 minority class에 대한 non-robust feature을 더하여 sample을 생성하는 형태이다.
Detailed components of M2m
1) Sample rejection criterion
synthetic sample을 생성할 때 중요한 것은, g classifier가 기존 class k_0에 대한 feature는 잘 제거하는 것이다.
그래야 k class의 sample을 제대로 생성했다고 판단할 수 있기 때문이다.
그러나 g classifier는 완벽하지 않기 때문에, k_0를 이용해 k class의 sample을 완벽하게 생성하지는 못한다.
그러므로 생성된 sample이 오히려 방해가 될 가능성이 있다.
(k_0에 대한 diciriminative한 feature가 남아있을 가능성이 있음)
이러한 risk는 특히 생성을 위해 사용하는 k_0의 sample수가 작을 경우 더 심해진다.
이러한 risk를 줄이기 위해서 저자는 synthetic sample을 일정 확률로 rejecting하는 방식을 제안한다.
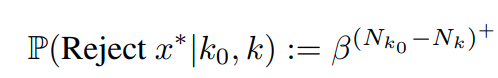
위 식의 의미는 N_k_0 - N_k의 max 값을 B의 exponential 값으로 이용하겠다는 것이며,
B의 값이 작을수록 classifier g의 reliability가 더 높다는 것을 의미한다.
예를 들어 B=0.999이면, sample을 accepted하는 probability가 N_k_0 - N_k > 4602일때, 99% 이상이다.
B=0.9999이면, N_k_0 - N_k > 4602일때 99% 이상이다.
이러한 모델링은 effective number 논문에서 참고한것이다.
위 논문에서, larger dataset에서 sample이 하나 추가될 경우 실제로 적용되는 효과는 exponentially하게 decrease된다고 한다.
(그냥 확률적으로 rejection 한다는 것이 불분명함)
만약 synthetic sample이 reject되는 경우, original dataset에 있는 minority sample을 대신 추가해준다.
2) Optimal seed sampling
그 다음 고려해볼만한 사항은 class k_0에 대한 majority seed sample x_0를 어떻게 선정할 것인가에 대한 내용이다.
이를 위해서 저자는 다음과 같은 Q(k_0 | k) 를 design 했다.
이때 2가지를 고려한다.
(a) Q는 acceptance probability P_accept(k0_|k)를 maximize 하도록 정한다.
(b) Q는 가능한 diverse class를 정하도록 한다. 즉 entropy H(Q)를 maximize하도록 한다.
결국 다음과 같이 식을 세울 수 있다.

이 optimization을 최대화하는 Q는 P_accept이다. (why?)
그래서 Q(k_0|k)는 다음과 같다.

위의 Q를 이용해 k_0가 결정되면 x_0는 uniform하게 random sampling 한다.
전 과정을 나타내면 다음과 같다.
