Paper
Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
Deep learning algorithms can fare poorly when the training dataset suffers from heavy class-imbalance but the testing criterion requires good generalization on less frequent classes. We design two novel methods to improve performance in such scenarios. Fir
arxiv.org
Code
kaidic/LDAM-DRW
[NeurIPS 2019] Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss - kaidic/LDAM-DRW
github.com
Introduction
Imbalanced data 문제는 보통 re-weighting, re-sampling 접근 방법을 많이 사용한다. 이는 train data distribution과 test data distribution을 동일하게 만듬으로써, 문제를 접근한다. 하지만 결국 minority class의 sample의 부족은 overfitting을 발생시킨다는 것은 큰 어려움이다.
그래서 저자는 majority class에 비해 minority class에 강한 regularizing 기법을 적용함으로써, minority class에 대한 정확도를 향상시키는 방법을 제안한다.
이는 기존의 weight matrix에만 regularization 방법을 적용한 것과 달리, label에도 함께 regularization 방법을 적용한다.
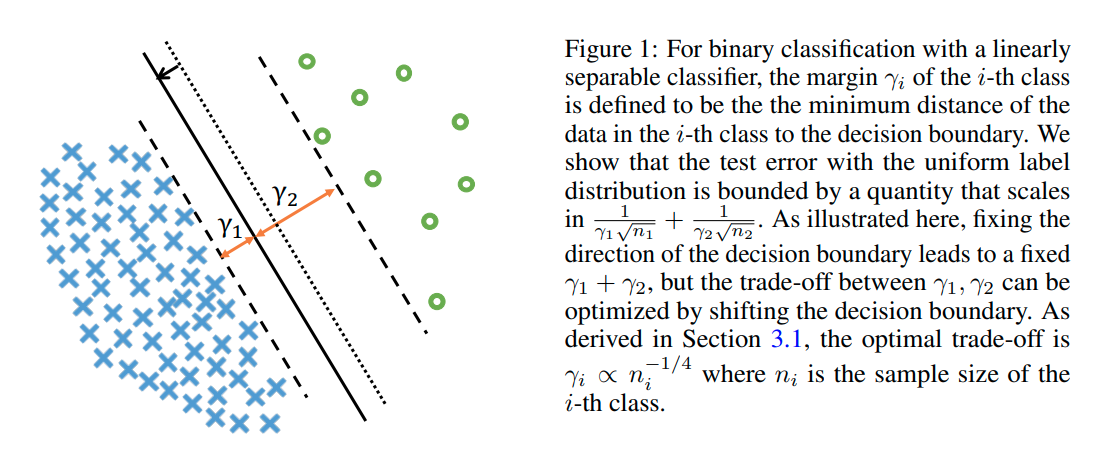
결론적으로 본 논문에서는 label-distribution-aware loss function을 적용함으로써, model의 margin을 minority class에 대해 좀 더 크게 되도록 최적화한다.
Main approach
1) Problem setup and notations
2) Fine-grained generalization error bounds.
일반적인 generalization error bound는 다음과 같다. (training , test data distribution이 동일한 경우)

이는 모델의 복잡도가 증가할수록 overfitiing이 잘되기 때문에, 복잡도에 비례하게 되고, training data 수가 많을수록
실제 data의 분포에 맞게 학습이 가능하기 때문에 error bound가 작아지게 된다.
그리고 training, test 모두 동일하게 imbalanced distribution인 경우, error bound는 다음과 같이 형성된다.

위의 식의 의미는 class간의 margin중에서도 최소값인 r_min이 크다는 것은 class 간의 boundary가 잘 형성되어있다는 의미이고, error의 최대값이 작아진다는 의미이다.
그러나 위 식에서는 label distribution에 대한 정보는 나타나 있지 않다.(oblivious)
그래서 다음과 같이 fine-grained하여 loss function을 다시 구성한다.

3) Class-distribution-aware margin trade-off
위의 margin 식을 살펴보면 class에 대한 sample의 수가 많을수록 error bound가 작아지는 것을 확인할 수 있다.
즉, minority class에 대한 error bound를 줄이려면 margin값을 크게 해야한다는 사실을 알 수 있다.
그러나 minority class에 대해 margin을 너무 크게 하면, majority class에 margin이 작아지는 단점이 있다.
그렇다면 optimal한 margin은 어떻게 구할 수 있을까?
class가 2개인 binary classfication 문제인 경우 balancd generalization error bound를 다음과 같이 나타낼 수 있다.
( 5번식 참고)

이때, r_1과 r_2는 복잡한 weight matrices이기 때문에 optimal margin을 구하기 어렵다.
하지만 이러한 방식으로 접근이 가능하다. 만약 margin r_1, r_2가 현재 optimal이라면,
shifted bias를 현재 margin에 적용했을때, 아래와 같이 error bound가 더 커져야 한다.

위 식은 다음과 같은 의미를 내포한다.
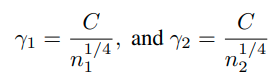
4) Fast rate vs slow rate, and the implication on the choice of margins.
generalization error bound에는 Fast rate와 slow rate라는 용어가 있다.
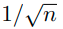
의 scale에 따라 bound가 변화하는 경우, 'slow rate'라고 부른다.

위와 같이 변화하는 경우 'fast rate'라고 부른다.
딥뉴럴넷이 충분히 큰 경우 위와 같이 fast rate로 바뀔 수 있다.
Label-Distribution-Aware Margin Loss
위의 binary classificaiton의 경우를 고려하여 저자는 multiple case에 대해서 다음과 같이 가정한다.
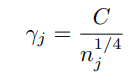
그리고 soft margin loss function을 위와 같은 margin을 가지도록 디자인한다. (optimal margin이므로)
(x,y)를 training example이라고 하고, f를 모델이라고 하자. 이때,

를 model의 j class에 대한 output이라고 정의한다.
이때 hinge loss를 이용해서
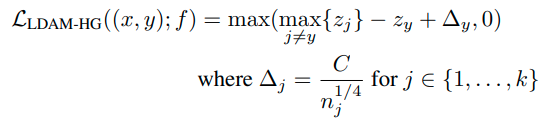
위와 같이 loss function을 구성가능하다.
위 식의 의미는 다음과 같다. label y에 대한 logit과 다른 클래스 logit의 max값의 차이가 최소 △는 되어야 한다.
그러나 hinge loss가 smooth 하지 않은 점은 optimization 과정에서 문제점을 만들어내고, 다음과 같이 cross-entropy loss에 margin을 부여해서 smooth한 hinge loss를 만들어 낼 수 있다.

label y에 대한 logit이 margin보다 커야 loss값을 줄일 수 있음
Deferred Re-balancing Optimization Schedule
re-weighting 방법과 re-sampling 방법은 imblanced dataset을 다루는 주요한 방법이다.
(둘다 uniform한 test distribution에 가깝게 만드는 방법이기 때문)
그러나 re-sampling 방법의 경우 model이 deep neural network인 경우 heavy overfitting이 나타난다고 알려져 있다.
그리고 re-weighting의 경우 optimazation이 불안정하다는 단점이 있다. (특히 extremely imbalanced인 경우)
그래서 이전 연구에서 이러한 optimization 문제를 다루기 위해 복잡한 learninig rate schedule을 적용한 바가 있다.
저자들은 re-weighting , re-sampling 방법 모두다 learning rate를 적절히 annealing 하지 않는 경우,
ERM보다 오히려 성능이 떨어지는 것을 발견하였다. (all training example에 대해 똑같은 weight를 주는 방법)
annealing을 하기 전에 re-sampling 및 re-weighting 방법으로 생성된 feature의 경우 오히려 안좋은 것으로 확인되었다.
그래서 다음과 같은 defered re-balancing training procedure를 만들었다.

먼저 LDAM loss를 vanila ERM (no weighting) 방법을 사용하여 training 시킨다. 그리고 이후에 smaller learinig rate를 이용해 re-weight LDAM loss를 적용한다. 실험 결과적으로 training의 first stage(no weighting) 는 second stage(weighting)의 좋은 초기화 방법이 된다.
Experiments
1) Baselines
(1) ERM loss : 모든 example에 대해서 똑같은 weight를 적용한 방법, standard cross-entropy loss를 사용한다.
(2) Re-Weighting(RW) : class의 sample size에 inverse하게 weighting한다.
(3) Re-Sampling(RS) : 각 example을 sampling할때, class sample size에 inverse하게 sampling
(4) CB : Class-balanced loss based on effective number of samples 논문 참고
(5) Focal Loss : Focal loss for dense object detection. 논문 참고
(6) SGD schedule : SGD를 learning rate dacay method 방법을 사용한 것.
2) Our proposed algorithm and variants.
(1) DRW and DRS : 먼저 Algorithm 1에 적힌 것 처럼 standard ERM optimization을 적용하고 그 다음 second stage때 re-weighting 및 re-sampling 방법을 적용하는 것을 말한다.
(2) LDAM : 본 논문에서 제안된 Loss function을 적용한 것.
3) Experimental results on CIFAR

HG-DRS 는 Hinge Loss+DRS
LDAM-HG-DRS는 Hinge Loss에 LDAM margin을 준 것,
M-DRW는 cross-enropy에 uniform margin을 줘서 사용한 것을 말한다.
Hinge Loss의 경우 100 class에서 optimization 이슈가 있어서 10개 클래스에서만 실험하였다.
Conclusion
1) LDAM loss를 통해 최적화 된 class 별 margn을 찾음 (binary를 통한 추론값을 multi class에 적용
2) 학습 초반 부터 re-weighting 및 re-sampling 기법을 적용하면 feature의 학습이 저해되는 부작용이 있는데,
처음에는 standard training 방법을 사용하고 이후에 re-weighting 및 re-samping을 적용하는 deferring 방법을 사용함.