Paper
Method

imbalanced problem의 근본적인 문제점은 minority class를 학습하기 위한 sample이 부족하다는 것인데, minority class에 대해서 4개의 anchor를 설정함으로 majority class에 비해 더 많은 학습 및 embedding을 형성하도록 하는 방법이다.
먼저 embedding 공간을 L2-norm이 1로 제한된 공간에 놔둔다.
- Quintuplet Sampling
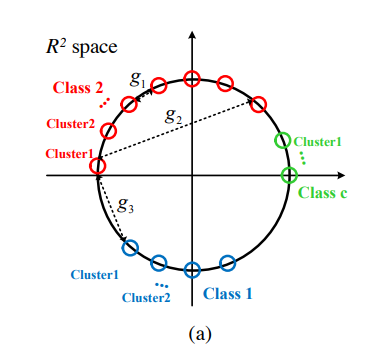
quintuplet은 다음과 같이 정의된다. (그림 참고)

이를 통해 다음과 같이 거리를 설정한다. (위 그림 참고)

이러한 quintuplet method는 2가지 메리트가 있다.
1) Triplet loss는 단순히 같은 class끼리는 당기고 다른 class는 떨어트리는 방식을 사용한다. 그러나 quintuplet은 class간과 class 내부의 instance level까지 같이 고려하기 때문에 더 rich한 feature를 추출할 수 있다는 장점이 있다.
2) under sampling 방법과 비교하면 information loss가 없고, over-sampling과 비교하면 주로 사용되는 artifitial noise가 없다는 장점이 있다. 실제 구현에서는 mini-batch에 minority class와 majority class 같은 숫자를 넣고 학습을 시킨다.
실제 구현에서 quintuplet을 선정하기 위해서는 이미 위 그림의 cluster들의 초기 형태가 형성되있어야 한다.
그래서 특정 데이터셋에서 pre-trained된 모델을 사용하여 feature를 추출하고 이를 통해 k-means clustering을 하여 cluster를 형성한다.
이러한 clustering을 좀 더 robust하게 하기 위해 5000 iteration마다 cluster 형성을 새롭게 업데이트 한다.
- Triple-Header Hinge Loss

위의 그림을 loss function형태로 구현 한 것이다. (잘 모르겠으면 margin loss 참고)
이와 같이 loss를 구현하면 실제로는 아래와 같이 embedding space가 구현된다.
learning하는 방식은 다음과 같다.

실제 학습할 때는 look-up table (dictionary 형태로 거리 저장한다는 의미인듯) 그리고 hardest한 학습은 피하기 위해서 실제 training set에서 50%만 random으로 sampling하여 사용한다.
요약하면 다음과 같다.

- Difference between "Quintuplet" Loss and Triplet Loss
Triplet Loss의 경우 class기반으로 같은 class 끼리는 뭉치게 만들고 다른 class sample끼리는 멀리 떨어지게 만들기 때문에, 실제 imbalanced data의 문제인 적은 sample 수를 가진 class의 적절한 boundary 혹은 margin을 표현하지 못할 수 있다. (실제로는 더 넓은 지역을 cover해야 하지만, few sample로는 넓은 지역을 다 cover 못할 수 있음)
이에 반해 Quintuplet의 경우, class 내부에 또 다른 cluster를 형성하며, 이는 class 내부에서 생기는 variance를 표현할 수 있다. 이를 통해서 좀 더 넓은 class의 margin 및 boundary를 형성할 수 있고. imbalance에서 생기는 적절한 boundary를 형성하는 문제에서 도움이 될 수 있다.
- Nearset Neighbor Imbalanced Classfication
본 논문에서는 Classification을 위해서 kNN Classification 방법을 사용한다.
기존 kNN과 차이점은 다음과 같다.
1) 기존 knn은 sample-wise로 classificaiton을 하였지만, 본 논문에서는 class마다 형성된 cluster-wise로 knn을 수행한다.
2) Classificaiton을 위해 다음과 같은 공식을 함께 이용한다.

요약하자면 assumtion 하는 class에 해당하는 가장 멀리있는 cluster와의 거리와 해당 class를 제외한 나머지 class의 cluster중에서 가장 가까운 거리를 계산해 차이를 구한다. 이때, 위 식의 값이 크다는 말은, 특정 class에 해당하는 cluster와를 max값을 취했는데도 작다. 즉, 가깝다는 의미이고, 특정 class를 제외한 class들과의 거리 중에서 가장 작은 값을 취했는데도 크다. 즉, 다른 class들과는 멀다는 의미이므로, 특정 class에 query가 가장 가깝다고 할 수 있다.
이러한 방식은 다음과 같은 장점이 있다.
1) imbalanced 환경에 더 강건하다:
기존 방법의 경우 가장 가까운 class의 개수를 통해서만 prediction하기 때문에 imbalanced 문제를 해결하기 힘드나 본논문에서 제시한 embedding 방법과 위의 classicification rule을 함께 적용하면, minority class에 대해서도 large margin을 가져갈 수 있기 때문에 강건한 결과를 낳는다.
2) cluster wise search를 수행하기 때문에 속도가 sample-wise에 비해 빠르다.
결론적으로 실제 동작하는 순서는 다음과 같다.
