Paper
Class-Balanced Loss Based on Effective Number of Samples
With the rapid increase of large-scale, real-world datasets, it becomes critical to address the problem of long-tailed data distribution (i.e., a few classes account for most of the data, while most classes are under-represented). Existing solutions typica
arxiv.org
Code
github.com/vandit15/Class-balanced-loss-pytorch
vandit15/Class-balanced-loss-pytorch
Pytorch implementation of the paper "Class-Balanced Loss Based on Effective Number of Samples" - vandit15/Class-balanced-loss-pytorch
github.com
Introduction
imbalanced-data 문제에서는 re-sampling, re-weighting 방법이 주로 적용된다.
이러한 방법은 주로 class frequency의 inverse하게 weighting을 적용했었다.
그러나 최근 연구에서 이러한 방법이 poor performance를 보였었고,
때문에 square root에 inverse 하여 weighting 하는 smoothed version이 제안되었다.
이러한 발견은 다음과 같은 의문을 낳게 되었다.
"다양한 imbalanced data에 따라 어떻게 class balanced weighting을 하는 것이 좋은 것일까?"
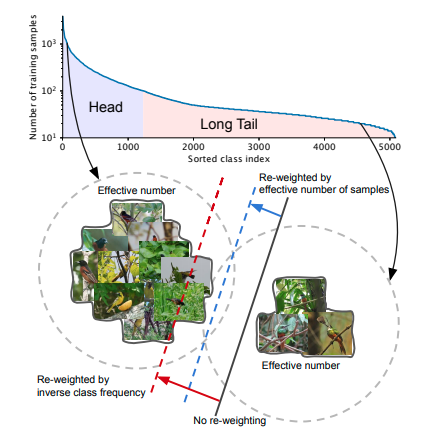
위 그림과 같이 highly imbalanced data에 바로 sample 수에 inverse하게 re-weighting 방법을 적용하는 것은 좋은 성능을 내지 못한다.
일반적으로 생각하기에는 data가 많을 수록 성능이 좋아지는 것이 맞지만, 비슷한 data가 추가되는 경우, 실제로 반영되는 효과는 낮다. 그렇기 때문에 각 class마다 'effective number'를 구하고 effective number를 기준으로 하여 re-weighting을 진행한다.
그래서 이 논문의 main contribution은 다음과 같다.
(1) long-tailed dataset을 다루기위한 effective number of sample의 이론적 분석 및 loss function에 적용하는 class balanced term을 design
(2) class balanced term을 기존의 loss function에 추가함으로써, 높은 성능 향상을 가져옴 (cross entropy, focal loss)
Effective Number of Samples
1) Data Sampling as Random Covering
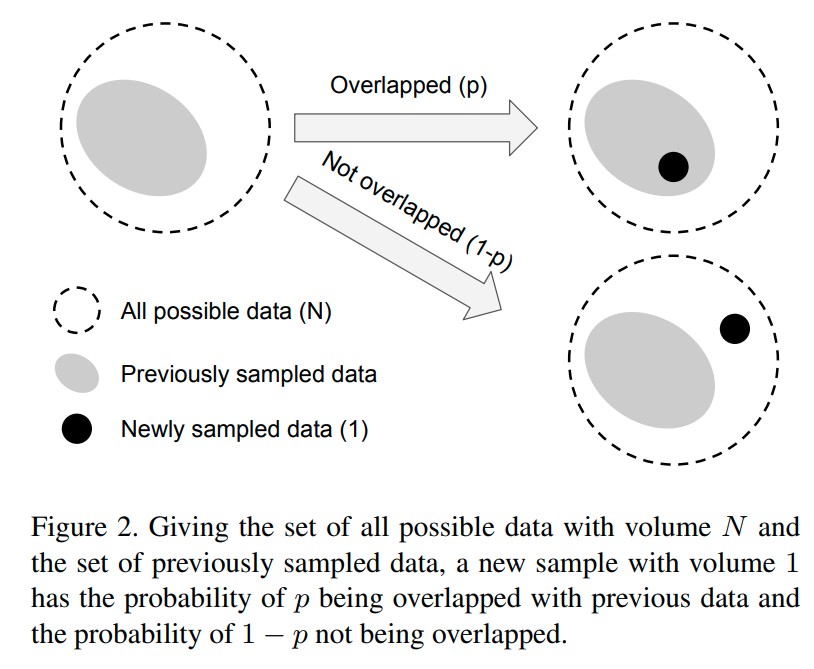
먼저 sample들의 effective number를 E_n으로 정의한다. 이때 n은 sampling된 example의 수이다.
수학적으로 너무 복잡해지는 것을 막기 위해 partially overlapped 되는 상황은 제외한다.
기존에 있던 data와 overlapped 되는 확률을 p, overlapped 되지 않는 경우를 1-p로 정의하며,
sampling을 진행할 수록 overlapped 될 확률이 커지기 때문에 p는 커지게 된다.
이때, effective number를 수식으로 나타내면 다음과 같다.

이 수식을 증명하는 과정은 다음과 같다.
먼저 E_1=1이다. (sample이 단 하나이므로 overlapping이 전혀 이루어지지 않기 때문에 당연한 결과이다.)
그러므로 다음과 같이 수식을 먼저 쓸 수 있다.

그리고 n-1개의 example을 sample하고 n번째 example을 sampling하는 경우를 생각해보자.
n-1개의 sample을 sampling했을 때, expected volume은 E_n-1이 된다. 이때, 새롭게 sample된 데이터가
overlapped될 확률은 다음과 같다.
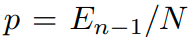
그러므로 n번째 example이 sampling되었을 때, expected volume은

와 같이 된다.
이때, E_n-1을 다음과 같이 가정하면

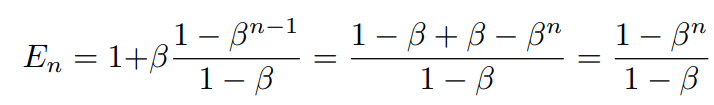
즉, 처음에 가정했던 식이 맞게 된다. (점화식 형태)
이는 samples의 effective number가 n의 exponential function이라는 것을 알려준다.
B는 0~1사이의 값을 가진다. E_n을 다른 형태로 표현하면 다음과 같다.

이 수식의 의미는 j번째 sample이 effective number에 영향을 주는 정도가 B^(j-1)이라는 것이다.
그래서 all possible data의 total volume은 다음과 같이 계산이 가능하다.

위 식을 토대로 다음과 같은 점근적 성질을 발견할 수 있다.
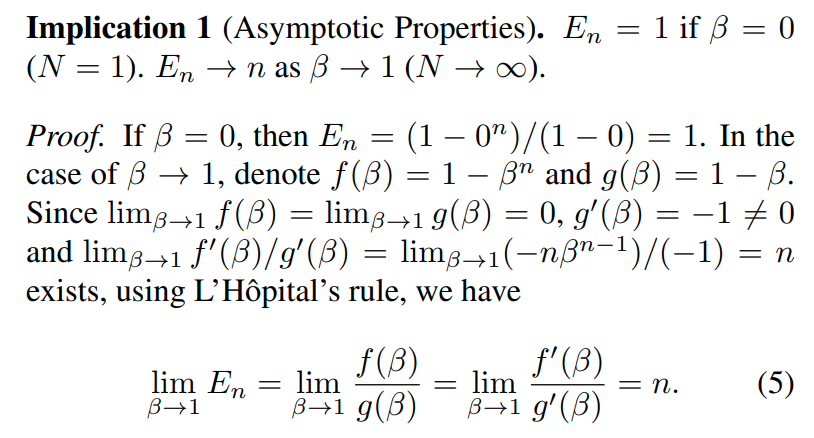
내용을 해석하면, all possible data N이 커질수록, effectve number of sample의 값은, 실제로 sampling된 숫자 n과 같게 된다.
즉, N이 커질수록 data overlap이 사라지고, 모든 sample이 unique해진다는 것을 의미하며, N=1인 경우는 오직 하나의 prototype만 존재하는 상황을 의미한다.
Class-Balanced Loss
input sample을 x , label을
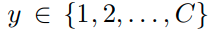
라고 정의하자. 이때 model이 각 class에 대해 prediction한 probability를 다음과 같이 정의한다.

위의 정의에 따라 loss를 L(p,y) , class i의 number of samples를 n_i라고 하자.
그러면 effective number of samples for class를 다음과 같이 나타낼 수 있다.


이때, N_i 를 특정하게 좋은 값으로 설정하는 건 어려운 일이기 때문에 다음과 같이 dataset에 맞게 설정한다.

class-balanced loss를 적용하기 위해서 weighting vector a를 적용한다.
이때 weighting은 class i에 대한 effective number of samples에 inverse하게 적용한다.

weighting을 적용했을 loss값의 scale이 달라지기 때문에 아래 식으로 나눠줌으로써, 다시 normalize해준다.
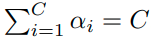
결론적으로 본 논문에서 제시하는 CB (class-balanced) loss는 다음과 같다.

이 loss function을 B를 변화시키며 나타내면 다음과 같다.

B가 1에 가까워질수록 inverse class frequncy에 맞게 re-weighting 된 것을 의미한다.
이러한 class-balanced loss는 모델이나 loss function에 general하게 적용이 가능한 장점이 있다.
본 논문에는 이를 증명하기 위해서 softmax cross-entropy loss, sigmoid cross-entropy loss, focal loss에 적용하였다.
Class-Balanced Softmax Cross-Entropy Loss

Class-Balanced Sigmoid Cross-Entropy Loss

Class-Balanced Focal Loss


Experiments
Imbalance factor는 가장 sample수가 많은 class의 sample 수와 가장 sample수가 작은 class의 sample을 나눈 값이다.
