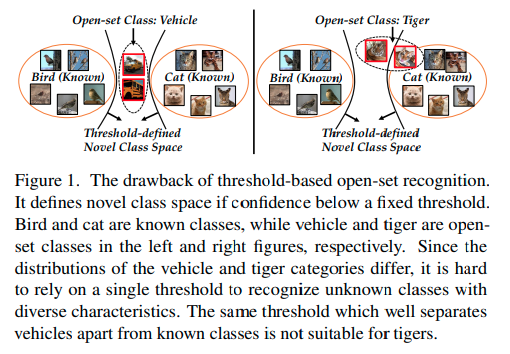
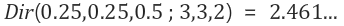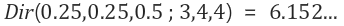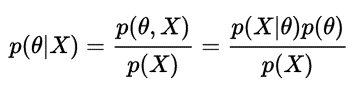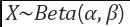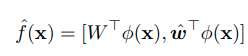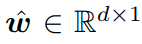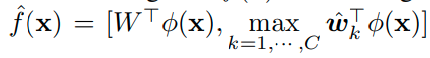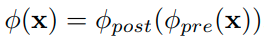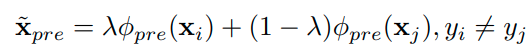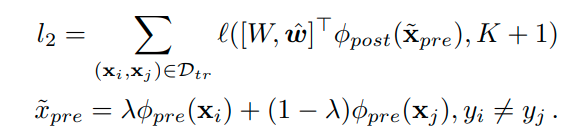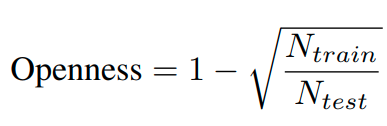기존 openset recognition 방법의 경우, logit 또는 softmax output 확률 값을 이용한 openset 방식을 사용하였다.
그러나 이러한 방법의 경우 위 그림 왼쪽과 같이 기존 클래스와 확연히 다른 경우 logit or softmax 값이 낮게 나와 openset 분류가 가능하지만, 위 그림 오른쪽과 같이 기존 클래스와 비슷한 클래스의 경우 기존 thresholding 방법으로는 구분이 어렵다.
(기존 closed set output과 비슷한 logit이 나옴)
이러한 문제를 해결하기 위해서 본 논문에서는 Novel Class 를 위한 Placeholder를 만든다.
먼저 기존의 closed-set 만을 표현하는 Classifier를 확장시킨다. (Augmented)
이때 추가된 Classifier를 classifier placeholder라고 표현한다.
이를 통해 각 클래스 마다 known과 unknown을 구분하는 class-specific threshold를 만든다.
(원래는 class마다 동일한 threshold로 known과 unknown를 구분하였음)
또한 novel class의 distribution을 학습하기 위해서 'data placeholder'를 이용한다. data placeholder는 manifold mixup을 활용하여 open class의 instance를 생성하며 이를 openset training data로 활용하여 training에 활용한다.
Method
- Learning Classifier Placeholders
Classifier Placeholder는 dummy classififer를 만들어주는 방법이다.
수식으로 표현하면 다음과 같다.
왼쪽의 경우 기존의 classifier이고 오른쪽의 경우 추가로 Augmented(추가된, 확장된) classifier weight이다.
이때, embedding network, phi는 둘다 같다.
그리고 dummy classifer는 일단 dummy class 하나만을 표현한다.
이러한 dummy classifier는 class마다 threshold를 지정하기 위해 사용되며, 따라서 특정 target class에 가깝게 embedding 되도록 유도한다. 따라서 아래와 같은 식으로 optimization 한다.
왼쪽의 loss식은 augmented된 classfier의 logit을 target class y에 optimization하는 것이고, (일반적인 classification loss와 같다고 보면 된다.) 오른쪽의 식은 augmented된 classifier에서 target class y를 제거하고, 이를 open-class, K+1 에 optimization하는 것이다. 이를 통해서 dummy classifier의 weight는 target classifier의 weight와 가까운 위치에 optimization이 된다. (target-class와 non-target class의 사이) 이때 하나의 class만이 아닌 모든 class y에 대해서 이를 행하게 되면 결국 dummy classifier를 중앙을 나타내는 weight가 된다.
이렇게 하는 이유는 따로 openset sample이 일단 없는 상황에서도 중앙 부분의 decision boundary를 형성하는 classifier를 만들기 위해서 이다.
이때 첫번째 loss term을 통해서 classification 성능을 유지하며, 두번째 loss term을 통해서 dummy classifier가 다른 class center (classifier weight) 보다 더 가깝게 위치하도록 유도된다.
이는 특정 instance가 기존에는 closed set으로만 prediction되도록 한정되어 있었다면, class 마다 closed-set 혹은 dummy classifier (open-class)로도 prediction 될 수 있도록 optimization하는 것이다.
-Learning multiple dummy classifiers
이러한 dummy classifier는 여러개를 사용할 수 있다. C개 만큼 사용하면 다음과 같이 표현이 가능하다.
이렇게 여러개의 dummy classifier를 사용하는 경우 dummy logit은 max값 하나만 이용한다.
(가장 가까운 dummy classifier만 업데이트, 나머지 다 하면 나머지도 그쪽 Class로 당겨짐.. 그럴 필요 없음)
이를 통해 openset class의 경계를 좀 더 디테일하게 설정이 가능하다. (경계가 여러개 벡터로 형성..)
-Learning Data Placeholders
논문에서는 openset boundary를 설정하기 위한 classifier placeholder 뿐만아니라 openset instance를 생성하여 learning에 활용한다. 이때 openset instance를 data placeholder라고 지칭한다.
openset instance를 생성하기 위해 manifold mixip을 사용한다. 먼저 layer를 다음과 같이 표현한다.
이때 manifold mixup를 pre-layer를 통과한 middle-level feature를 통해서 수행하며 수식으로 표현하면 다음과 같다.
이때 람다는 Beta distribution에서 sampling하며 결정한다. (Mixup, Manifold Mixup에서 사용한것과 동일함)
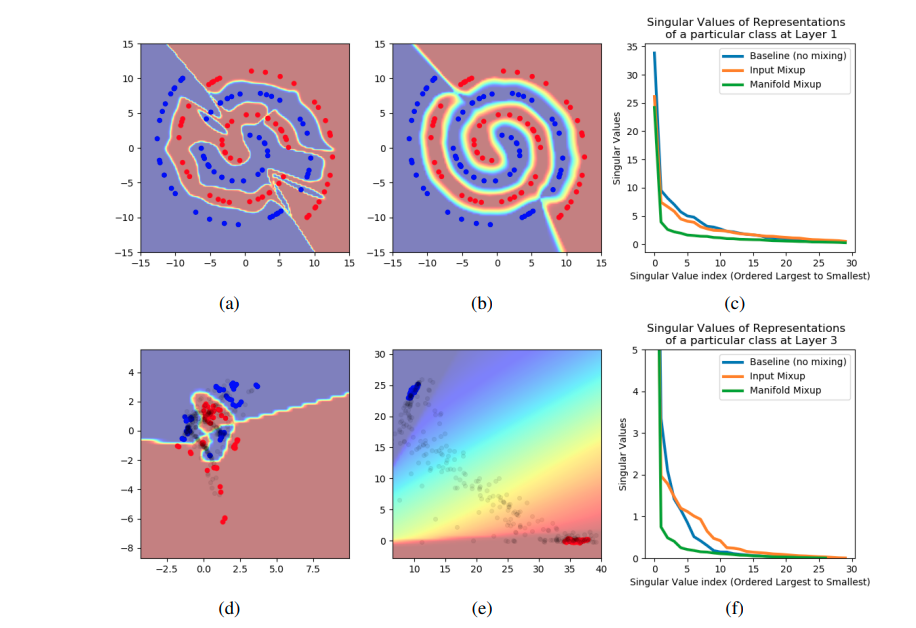
manifold mixup을 사용하는 이유는 이를 통해서 low-confidence를 만들 수 있기 때문이다.
(이 부분은 manifold mixup 논문을 읽어봐야 할듯 함)
이러한 mix-up 과정은 mini-batch 내에서만 이루어진다.
이를 통해 생성된 x_pre를 openset instance로 분류하며 아래와 같이 openset으로 분류하도록 트레이닝한다.
이를 그림으로 나타내면 아래와 같다.
Discussion about vanilla mixup
왜 vailla mixup이 아니라 manifold mixup을 활용했는가?
본 논문의 저자는 다음과 같이 주장한다. (솔직히 뭔소린지 모르겠음)
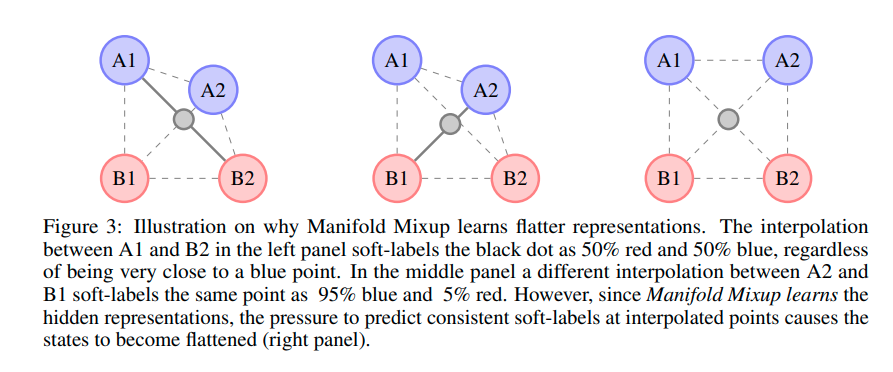
- vanilla mixup을 활용할 경우 다음과 같이 mix한 결과가 openset instance가 아닌 another class k instance와 유사할 수 있음
-> 근거없는 주장인듯
그러나 manifold mixup의 경우 can move the decision boundary away from the data in all directions
-> manifold mixup 논문을 봐야될듯..
Calibration and Guideline for Implementation
Closeset의 경우에 high-confidence가 나오지만, openset의 경우 open-class instance및 dummy classifier 또한 embedding space의 중앙에 위치하기 때문에 confidence 값 자체가 기본적으로 낮게 나온다.
때문에 dummy classifier를 이용해 openset을 분류할 경우, logit값의 크기를 맞춰주는 Calibration 작업이 필요하다.
Calibration 작업을 수행하기 위해 val dataset을 사용한다.
val dataset 을 이용해 다음을 계산한다.
결과적으로 다음과 같이 bias를 추가하여 calibtration을 한다.
이때 bias의 값은 val dataset의 95% 이상이 known으로 예측되는 값을 이용한다.
(val dataset이 known data로만 이루어져 있기 때문)
Training process of PROSER
Experiment
openess 정의
이때 N_train은 train class의 개수를 의미하며, N_test는 test때 class의 개수를 의미한다.
예를 들어 cifar10의 경우 train class는 6개이며, test class 개수는 10개가 된다.
계산을 하면, 1- root ( 6/10) = 22.54%가 된다.
이런식으로 계산을 하면 각 데이터셋 마다 다음과 같은 Openness score가 나온다.
mnist, svhn, cifar10 : 22.54%
cifar+10 , cifar+50 : 46.55% , 72.78%
Tiny-imageNet : 68.37%
backbone : GdFR과 같은 backbone
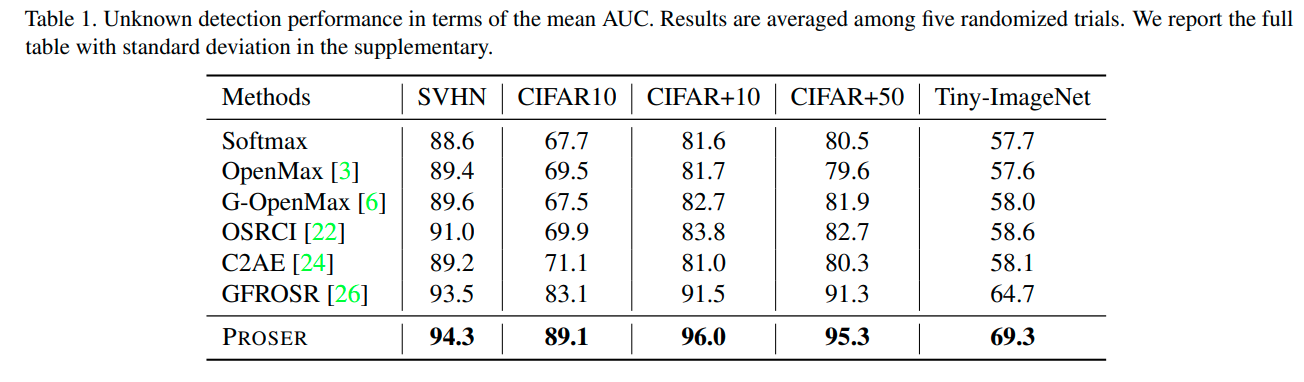
결과는 다음과 같음 (AUROC)
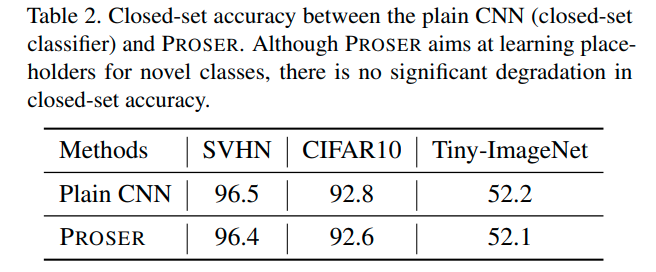
- Plain CNN과 Closed-set acc 비교
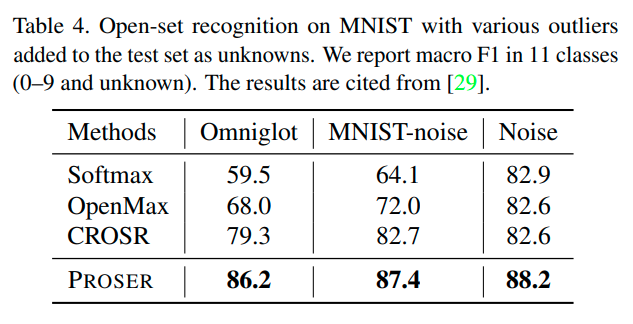
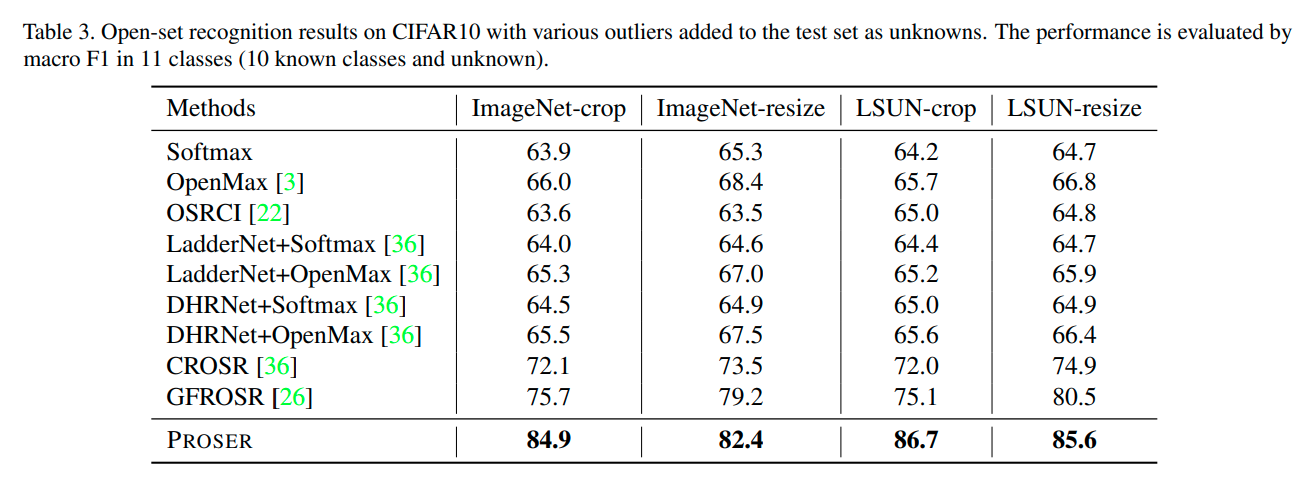
Openset Recognition Test
- GdFR metric 그대로 사용하였음
- MNIST와 Cifar10 데이터셋으로 학습시킨 후 ImageNet-crop, resize & LSUN-crop , resize Test dataset을 openset으로 test
- macro-averaged F1-scores로 측정한다.
- Mnist 같은 경우 known과 unknown dataset을 1:1로 구성한다.
-Cifar-10 같은 경우, Imagenet과 LSUN dataset으로 test를 하는데, Cifar-10과의 이미지 resolution을 맞추기위해서 32x32로 resize하거나 crop하여 test한다.
Ablation study
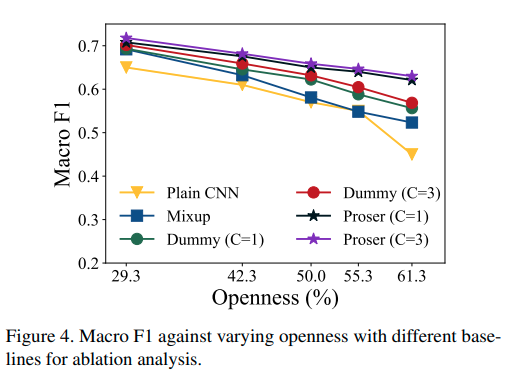
본 논문에서는 Cifar100 dataset에서 ablation study를 수행했으며, 100개의 Class 중에서 15개의 class는 known, unknown class는 다음과 같이 조절하면서 실험하였다. (randomly selected) 이에 따른 openness는 29.29% ~ 61.28%로 변한다.
위와 같은 setting으로 macro F1-score를 측정했으며, 결과는 아래와 같다.
이때 Mixup은 data placeholder 만을 사용한 것이며,
Dummy는 classifier placeholder만을 사용한 것이다.
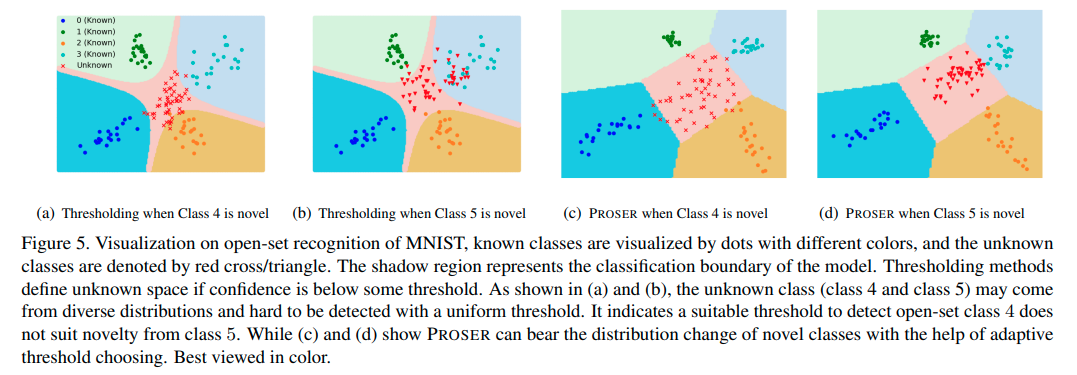
Visualization of Decision Boundaries
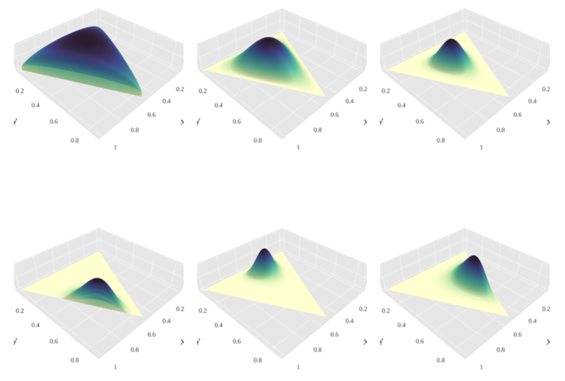
위는 decision boundary를 visualization한 것이다. 첫번째와 두번째 그림은 일반적인 thresholding method를 사용했을 때, decision boundary를 나타낸 것으로, 4번 Class가 openset으로 들어왔을 때는 어느정도 openset으로 잘구분을 하지만, 5번 Class가 openset으로 들어왔을 때는, closed set과 상당히 많이 겹치는 것을 확인할 수 있다. (하늘색 부분 확인)
그러나 PROSER의 경우, Class마다 적절한 decision boundary를 결정할 수 있고 따라서 class 5도 잘 구분할 수 있게 된다.
(이 부분에 대해 좀 더 생각해 봐야 될 듯)
Pros
- open class 에 대한 logit을 따로 설정하였기 때문에, 고정된 threshold (특정 Logit 값)으로 openset을 분류하는 것이 아니라
adaptive하게 (open class의 Logit이 특정값이 아니라 다른 클래스에 대한 logit보다 높은 값이면 openset) openset으로 분류가 가능하다.
- Manifold mixup을 활용하여 decision boundary를 smoothing하고, 또한 low confidence sample을 openset instance로 활용한 것이 도움이 되었음
Cons
- 여전히 feature가 유사한 클래스를 처리하는 방법은 없지않나.. 생각해봄.
Comparison with another papars
- RPL과 비교하면 유사한점은 openset을 featrue space의 중앙으로 mapping 시키도록 유도한다는 점이다.
- 차이점은 openset만을 위한 logit을 따로 두어 adaptive한 openset threshold를 설정한다는 장점이 있다.
- 또한 Manifold Mixup을 활용하여 openset training을 한다는 장점이 있다.
(RPL도 openset training 형태가 들어가 있기는 하지만 본 논문이 좀 더 적합해 보임)
(RPL은 Meta learning 형태로 기존의 closed-set을 openset으로 가정하여 trainig하기 때문에 실질적으로 openset이라고 보기 힘듬)
(그러나 manifold mixup은 실질적으로 low-confidence sample을 생성한 것이기 때문에 좀 더 적합한 openset sample이라고 생각함.)