728x90
728x90
'Dic' 카테고리의 다른 글
| jeffreys prior (0) | 2021.03.18 |
|---|---|
| Kernel (Bayesian statistics) (0) | 2021.03.18 |
| Beta distribution (0) | 2021.03.04 |
| ML & MAP (0) | 2021.03.04 |
| Fov (Field of View) (0) | 2021.02.22 |
| jeffreys prior (0) | 2021.03.18 |
|---|---|
| Kernel (Bayesian statistics) (0) | 2021.03.18 |
| Beta distribution (0) | 2021.03.04 |
| ML & MAP (0) | 2021.03.04 |
| Fov (Field of View) (0) | 2021.02.22 |
medium.com/@kim_hjun/beta-%EB%B6%84%ED%8F%AC-728d7453dc33
Beta 분포
Beta dist. 학부의 대부분 기초 통계학 수업에서 쉽게 찾아볼 수 있는 분포이자, Bayesian Statistics에서의 기본이 되는 Coin Toss 예제에서 본격적으로 그 유용성이 강조되는 분포.
medium.com
| Kernel (Bayesian statistics) (0) | 2021.03.18 |
|---|---|
| Predictive Distriution (0) | 2021.03.05 |
| ML & MAP (0) | 2021.03.04 |
| Fov (Field of View) (0) | 2021.02.22 |
| End-to-end learning (0) | 2021.01.11 |
베이지언 확률(Bayesian Probability)
갑자기 블로그를 처음 시작했던 2013년 1월달이 생각납니다. 그 때는 처음 시작하는 마음이라 거의 하루에 한개씩 글을 올렸던 것 같습니다 ^^. 새해가 되어서 그런걸까요.. 그때만큼은 아니지만
darkpgmr.tistory.com
베이즈 정리, ML과 MAP, 그리고 영상처리
고등학교 수학에서 조건부 확률이라는 걸 배운다. 그런데 그게 나중에 가면 베이지안 확률이라는 이름으로 불리면서 사람을 엄청 햇갈리게 한다. 1. 베이즈 정리 베이즈 정리(Bayes's theorem) 또는
darkpgmr.tistory.com
| Predictive Distriution (0) | 2021.03.05 |
|---|---|
| Beta distribution (0) | 2021.03.04 |
| Fov (Field of View) (0) | 2021.02.22 |
| End-to-end learning (0) | 2021.01.11 |
| Sampling with replacement (0) | 2021.01.07 |
[렌즈] 머신 비전 광학계 및 기초 용어 설명
소개 머신 비전에서 광학계는 정말 중요합니다. 여기서 광학계란 카메라, 렌즈, 조명까지를 일컫습니다. 물리적인 광학계가 잘 구성되었다면 검사 알고리즘이 편해질 것이고, 그렇지 않다면 알
luckygg.tistory.com
구성된 광학계로 얻을 수 있는 가로(H) 또는 세로(V) 영역을 의미합니다.
| Beta distribution (0) | 2021.03.04 |
|---|---|
| ML & MAP (0) | 2021.03.04 |
| End-to-end learning (0) | 2021.01.11 |
| Sampling with replacement (0) | 2021.01.07 |
| Bayes optimal classifier (0) | 2021.01.04 |
Paper
When Does Label Smoothing Help?
The generalization and learning speed of a multi-class neural network can often be significantly improved by using soft targets that are a weighted average of the hard targets and the uniform distribution over labels. Smoothing the labels in this way preve
arxiv.org
Abstract
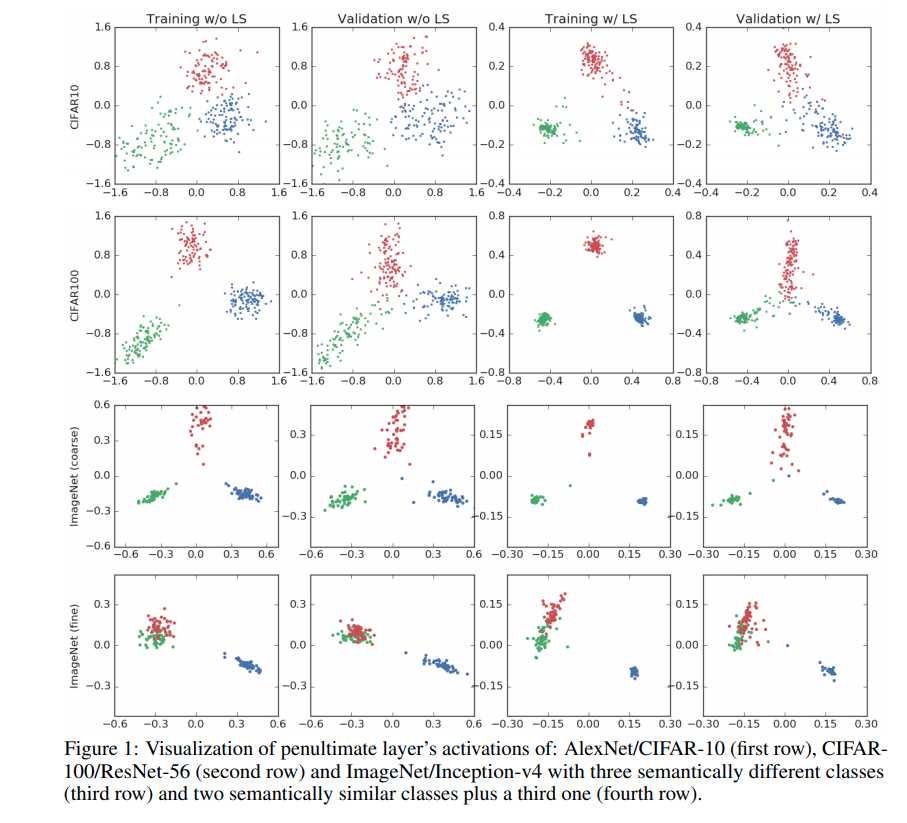
label smoothing을 적용하면 same class의 training example이 더 뭉치는 (tight) 형태로 representation이 형성되게 된다.
Penultimate layer representations
label smoothing을 하는 경우 uniform distribution에 fitting하는 항 때문에 input x가 incorrect class간의 같은 거리를 형성하도록 loss가 주어지게 되고, 결과적으로 embedding space에서 같은 class (intra class)끼리 좀 더 뭉치는 형태를 띄게 된다.
Paper
Soft Labeling Affects Out-of-Distribution Detection of Deep Neural Networks
Soft labeling becomes a common output regularization for generalization and model compression of deep neural networks. However, the effect of soft labeling on out-of-distribution (OOD) detection, which is an important topic of machine learning safety, is n
arxiv.org
Abstract
- Soft labelling 학습이 OOD detection에는 어떠한 영향을 미치는지에 대해 분석한 workshop 논문.
- incorrect-class에 대한 output의 soft-labeling 학습이 OOD detection 성능을 저해(deteriorate) or 향상(improve) 할 수 있다.
Introduction
저자는 실험을 통해 다음과 같은 가설을 제시한다.
a) label smoothing은 DNN의 OOD detection 성능을 저해한다.
b) teacher model을 통해 생성된 soft-label은 OOD-detection 성능을 student model로 동등하게 전달한다.
Soft Labeling as an Output Regularization
Soft labeling 기법은 주로 Noisy labelling 분야에서 Regularization 기법으로 주로 사용된다.
towardsdatascience.com/label-smoothing-making-model-robust-to-incorrect-labels-2fae037ffbd0
Label Smoothing: Making model robust to incorrect labels
1. Introduction
towardsdatascience.com
다음과 같이 uniform distribution를 이용해 regularization 하기도 하고,
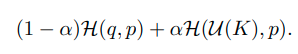
knowledge distillation에서는 teacher model의 output을 이용해 regularization 한다.
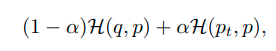
Experimental Setting
실험 세팅은 outlier exposure official code를 그대로 사용하였고, epoch 150만 학습했다는 점이 다른 점이다.
hyper-parameter setting은 다음 논문을 참고하였다. (when does label smoothing help? : NeurIPS 2019)
Label Smoothing and OOD Detection
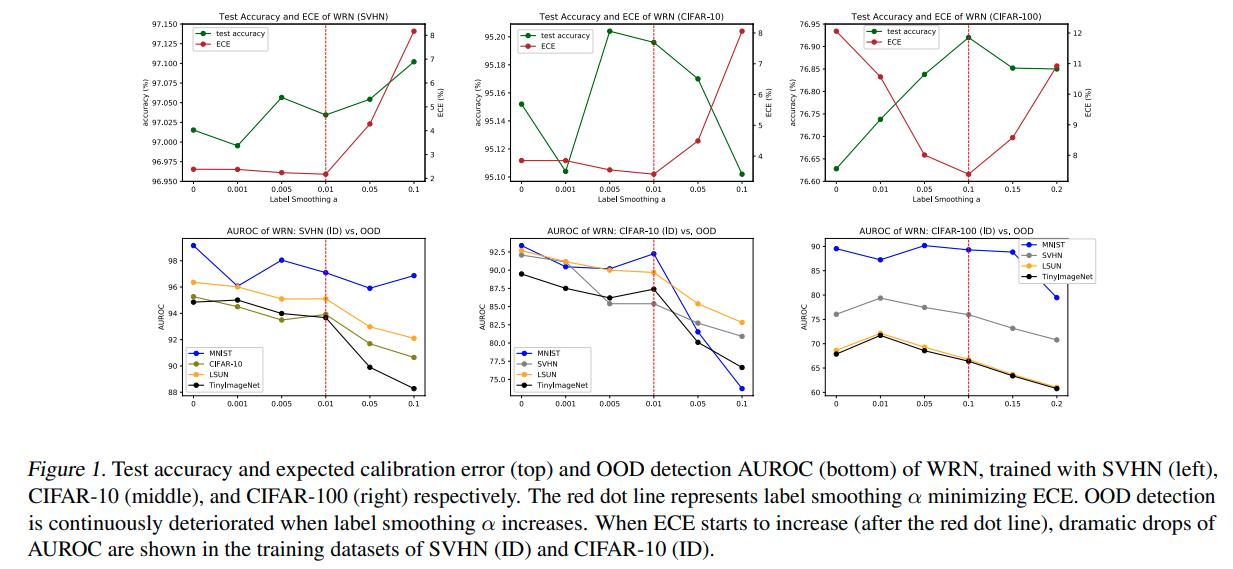
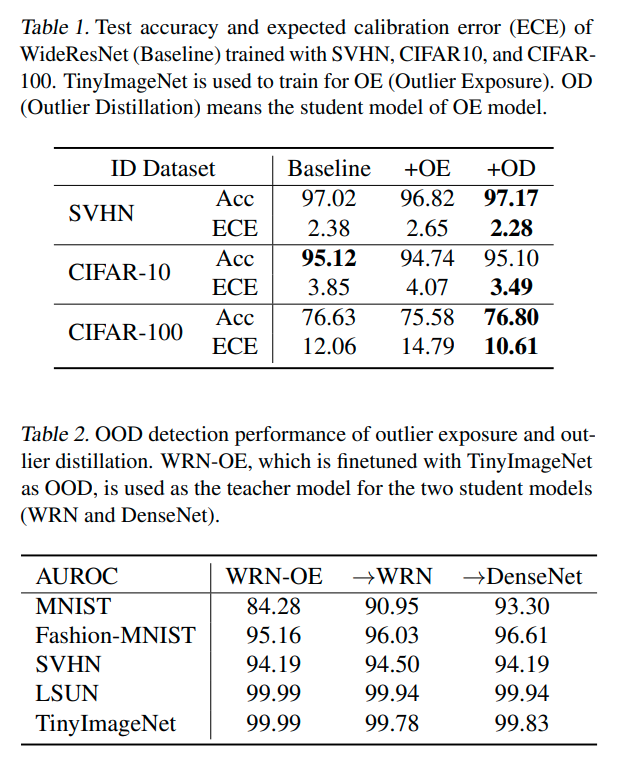
- label smoothing에 대한 결과 test acc 를 증가시키고 ECE를 감소시키기는 하였으나 AUROC는 감소시키는 결과를 낳았다.
(*ECE: expected calibaration error , acc와 confidence의 차이를 말하는듯..)
- 그럼 왜 AUROC가 감소하는가? ID(In-distribution) sample에 대해서 uniform distribution regularization을 적용하기 때문에
OOD가 위치하는 embedding space의 중앙 부분에 ID sample이 위치하는 결과를 낳기 때문이다.
- 위의 실험 결과에서 보듯이 Regularization term 'a'가 커질수록 AUROC는 감소하는 경향을 보이게 된다.
Knowledge Distillation and OOD Detection
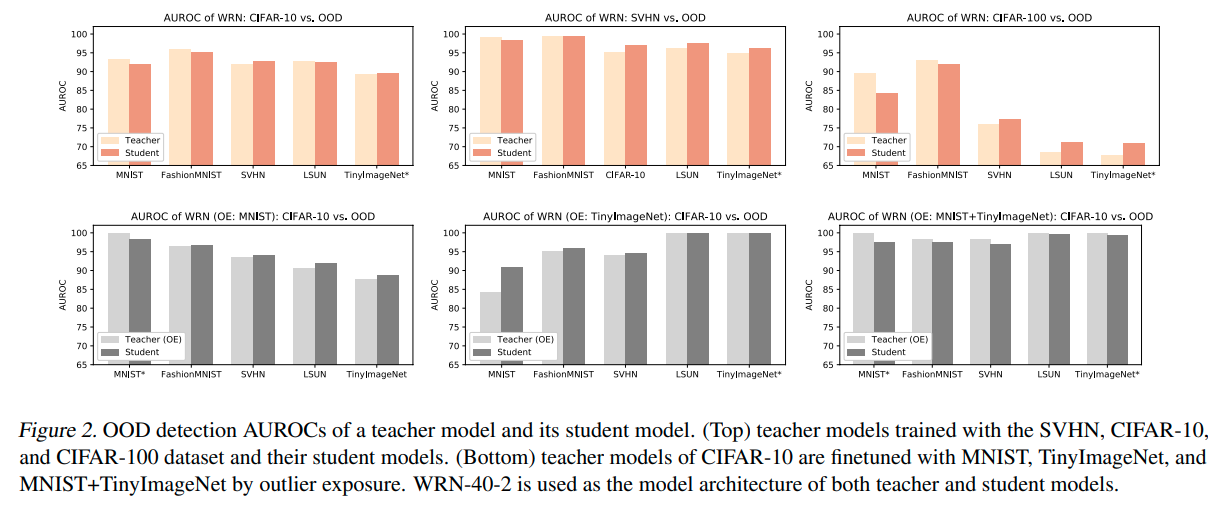
- 위는 OE없이 distillation한 결과이다. teacher model과 비슷한 결과를 가져간다고 논문에서는 말하고 있다.
- 아래는 OE를 학습한 teacher model을 가지고 distilation한 결과이다. teacher model의 AUROC값을 그대로 학습하는 것을 확인가능하다.
-이 실험의 경우, OE에 의해 학습된 teacher model의 Knowledge를 이용해 soft labeling 학습을 하여 AUROC를 높혔지만, 반대로 생각해보면 어찌되었든, soft-label 학습을 통해 AUROC을 높일 수 있는 방법이 존재한다는 것을 의미한다.
(그러나 준비된 teacher-model없이 어떻게 soft-labeling을 생성할지는 아직 숙제이다.)
- 또한 이러한 distiling을 모델의 크기에 관계없이 적용이 가능한 것으로 확인되었다.
(큰 teacher model로 부터 작은 student model로 distiling해도 teacher AUROC 학습됨)
| Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples : ICLR 2018 (0) | 2021.07.11 |
|---|
Paper
AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data
The success of deep neural networks often relies on a large amount of labeled examples, which can be difficult to obtain in many real scenarios. To address this challenge, unsupervised methods are strongly preferred for training neural networks without usi
arxiv.org
Code
github.com/maple-research-lab/AET
maple-research-lab/AET
Auto-Encoding Transformations (AETv1), CVPR 2019. Contribute to maple-research-lab/AET development by creating an account on GitHub.
github.com
AET: The Proposed Approach
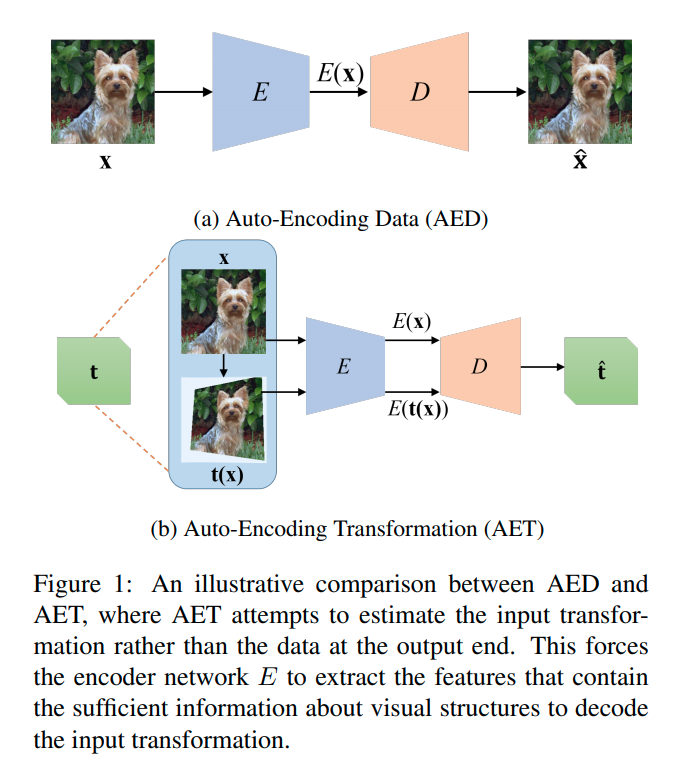
특정한 transformation을 이용해 image를 변환하고 변환 전 image x 와 변환 후 image t(x)를 encoding한다.
이를 이용해 decoding하여 transformation을 예측하게 하고, 실제 transformation t와 예측된 transformation t(hat)
을 비교하여 loss-function을 구성한다.
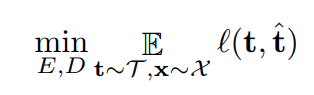
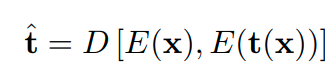
| argparse boolean 값 인자로 받기 (0) | 2021.05.01 |
|---|---|
| Python 편집기: 찾아바꾸기 (0) | 2021.04.29 |
| partial (0) | 2021.01.27 |
| Functools Partial (0) | 2020.09.01 |
| Dynamic Variable (0) | 2020.08.19 |