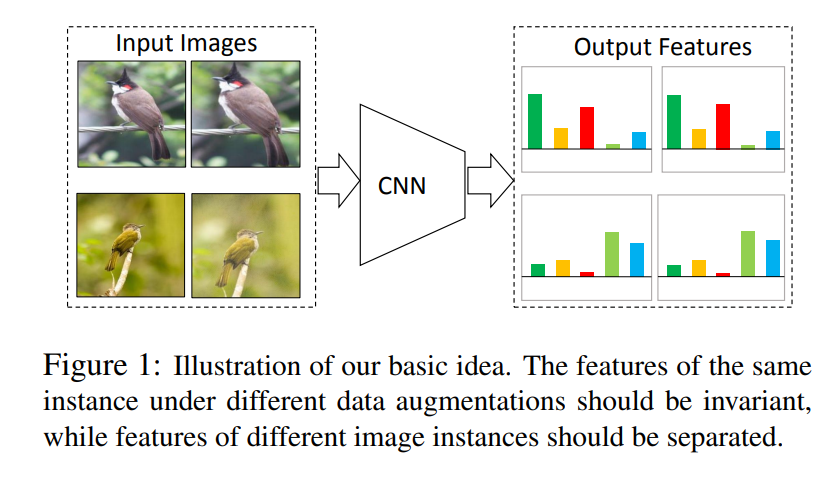
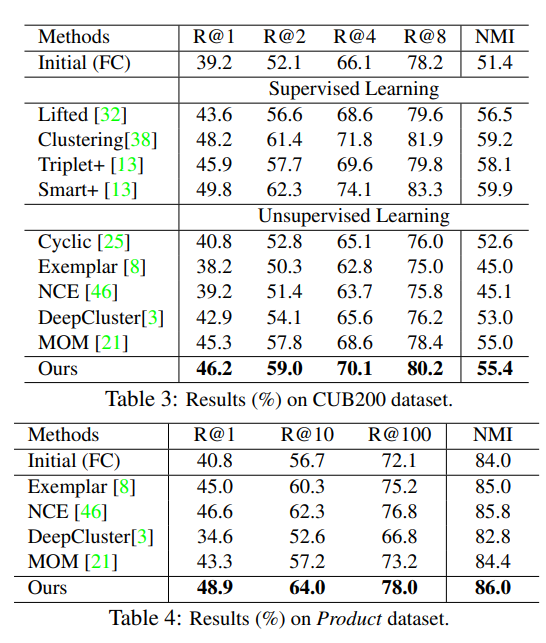
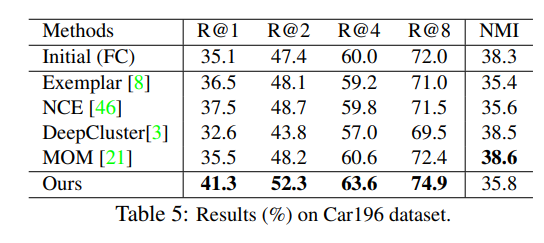
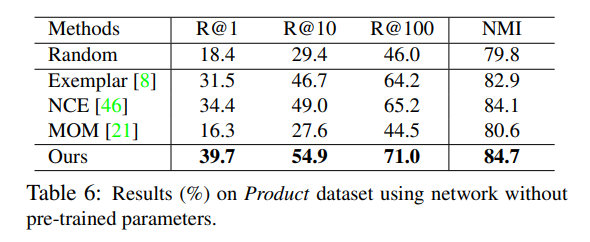
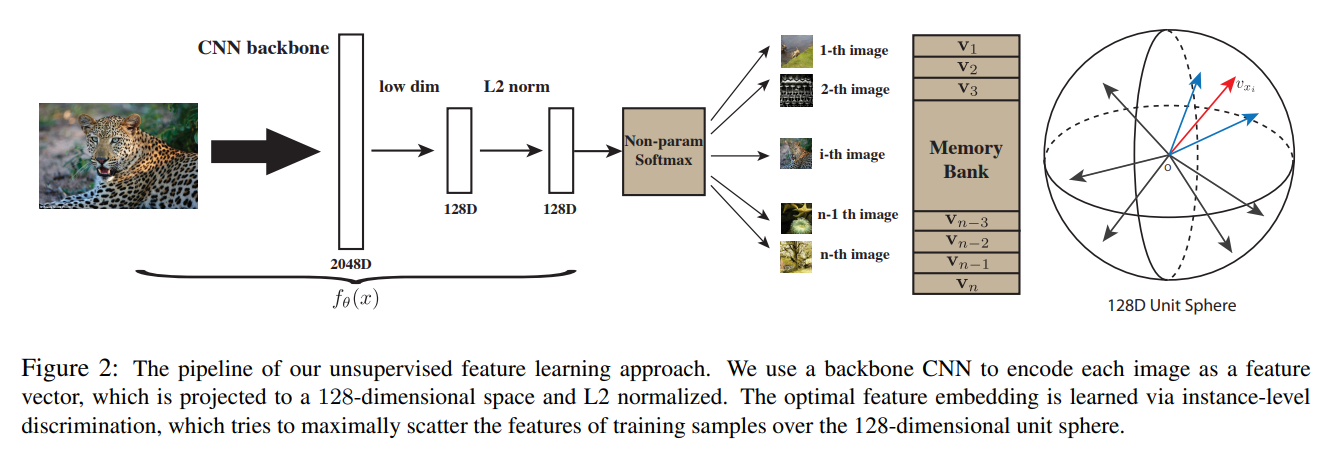
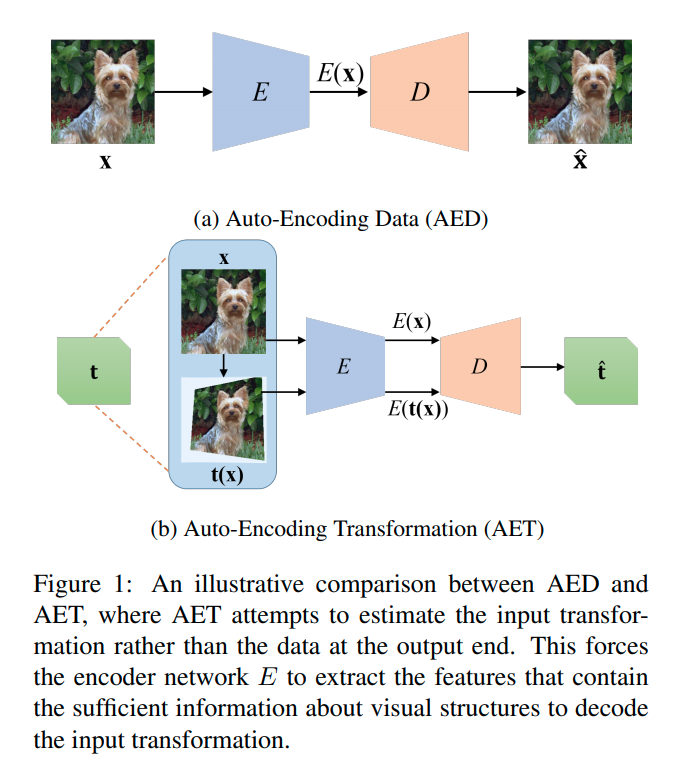
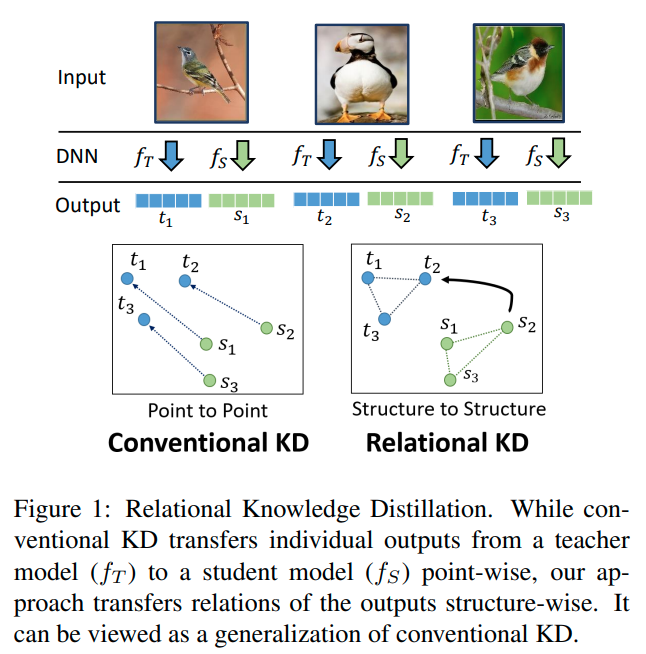
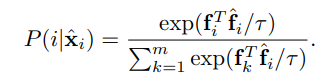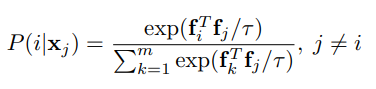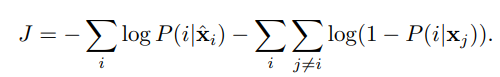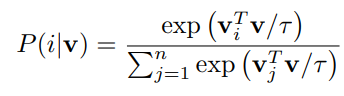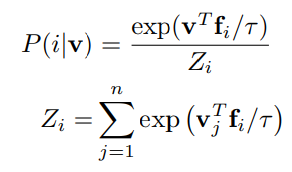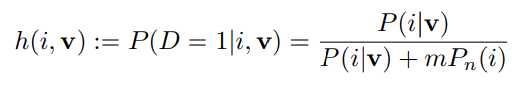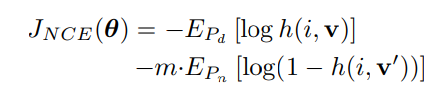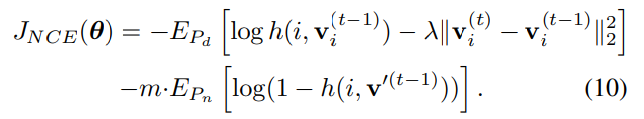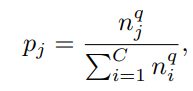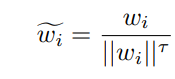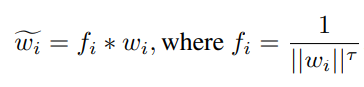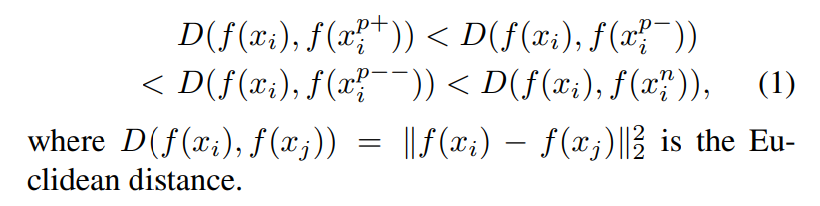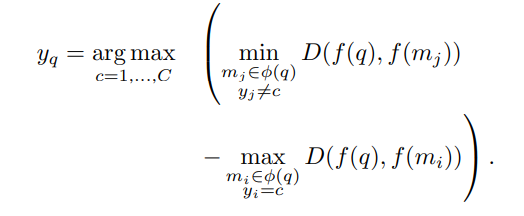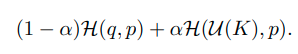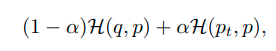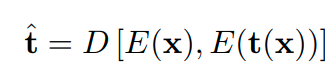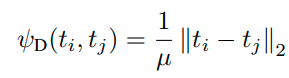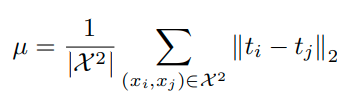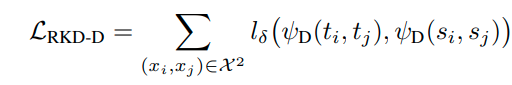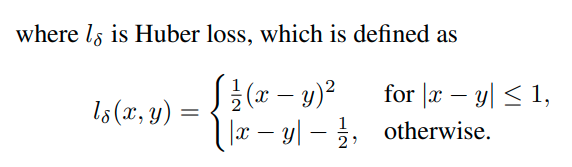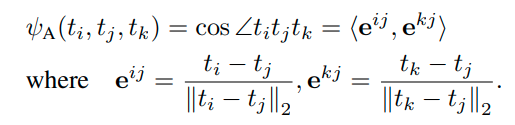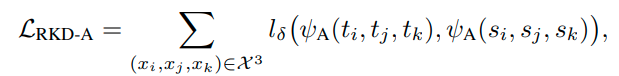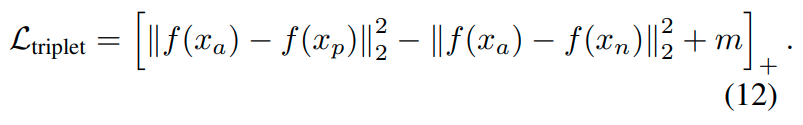image를 instance level로 같은 이미지는 가깝게 embedding하고 다른 이미지는 멀리 embedding시킨다.
위 그림은 한 이미지에 augmentation을 적용하기 전 이미지와 후 이미지를 같은 output feature가 나오게 만든다는 의미이다.
이러한 방법을 논문에서는 positive concentrated, negative separated라고 표현한다.
instance-wise한 방법은 general한 feature를 추출하기 때문에 unseen testing categories 구분에도 도움이 된다고 알려져 있다. (Dimensionality Reduction by Learning an Invariant Mapping)
수식은 다음과 같다.
먼저 augmented sample i가 i로 classified 될 확률은 다음과 같다.
sample xj가 instance i로 recognized될 확률은 다음과 같다.
그래서 augmented sample i 가 i로 classifed되고 j로 prediction되지 않을 확률은 다음과 같다.
이 수식에 대한 negative log likelihood를 계산하면,
이를 batch내에 있는 모든 instance에 대해서 계산하면 다음과 같다.
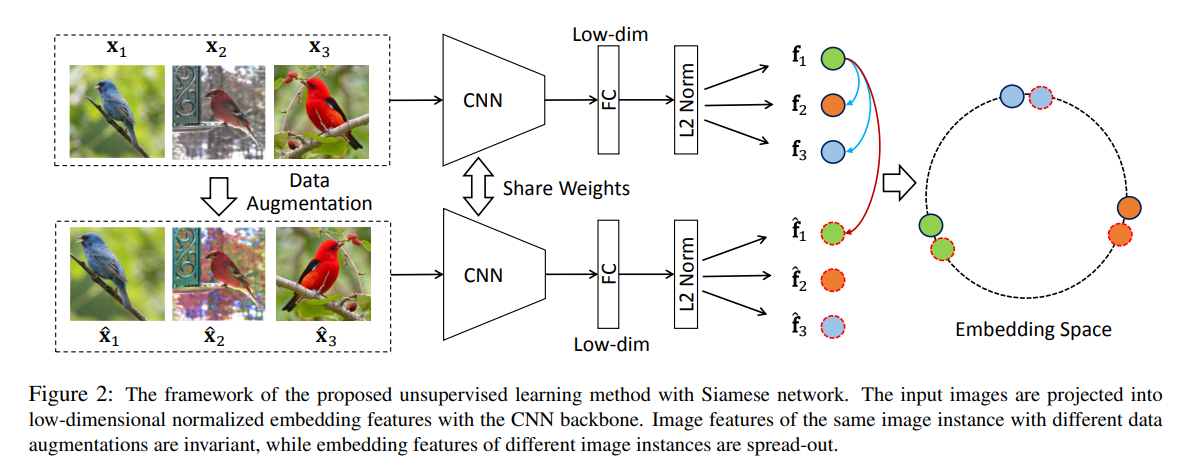
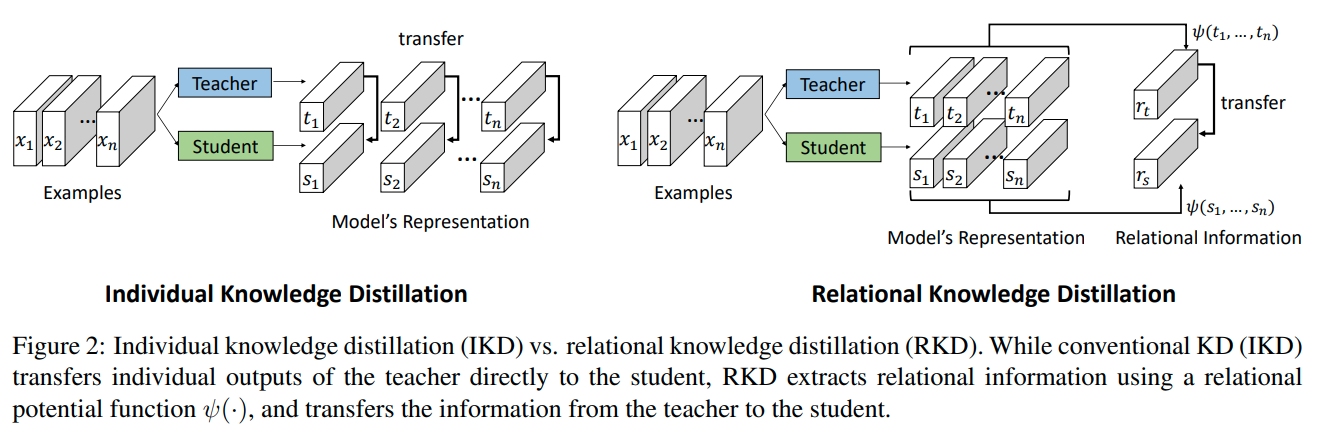
또한 training을 위해서 Siamese Network를 사용한다.
augmented sample의 feature를 뽑기 위함이며, 상세한 사항은 위 그림을 참고하면 된다.
Imagenet dataset을 기존의 supervised learning 형태로 학습시키게 되면 위와 같이 input image에 대해 유사한 class들이 softmax output에서 높은 값을 나타내는 것을 확인할 수 있다.
이는 일반적인 supervised learning이 class별로 annotation을 하여 학습시키기는 하지만 결과적으로 image간의 유사성을 스스로 학습할 수 있다는 의미를 나타낸다.
이러한 결과를 토대로 본 논문에서는 class-wise learning을 instance-wise learning 형태로 변형하여 시도한다.
Can we learn a meaningful metric that reflects apparent similarity among instances via pure discriminative learning?
그러나 이러한 방법을 사용할 경우, imagenet dataset 기준으로 class의 수가 1000개에서 1.2 million개로 늘어나게 된다.
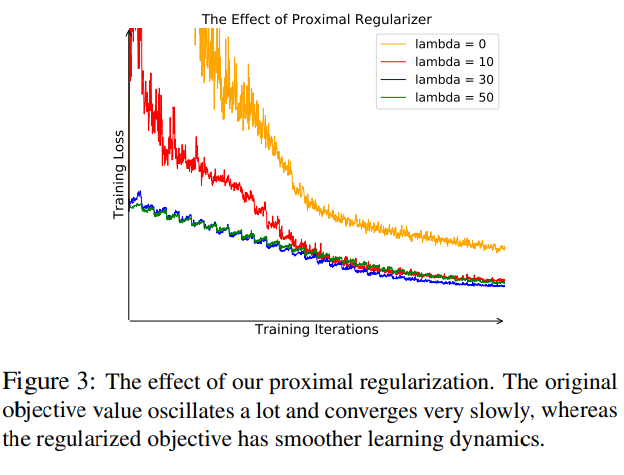
단순히 softmax를 이용해서는 이러한 class수를 다루기 어렵기 때문에, NCE 및 proximal regularization 방법을 활용한다.
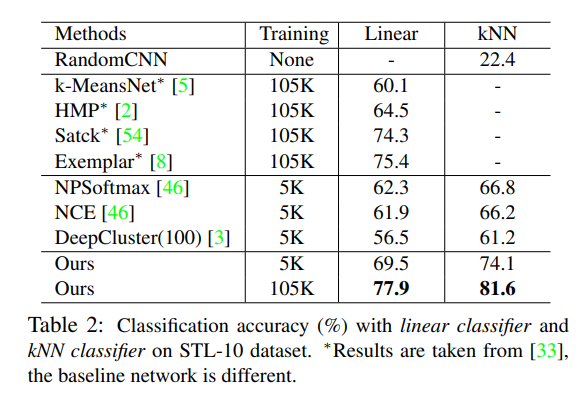
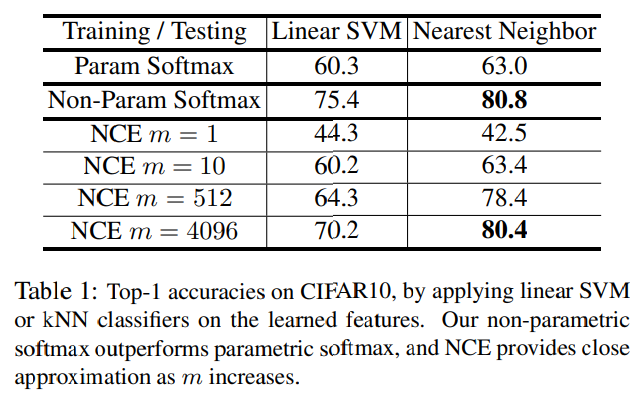
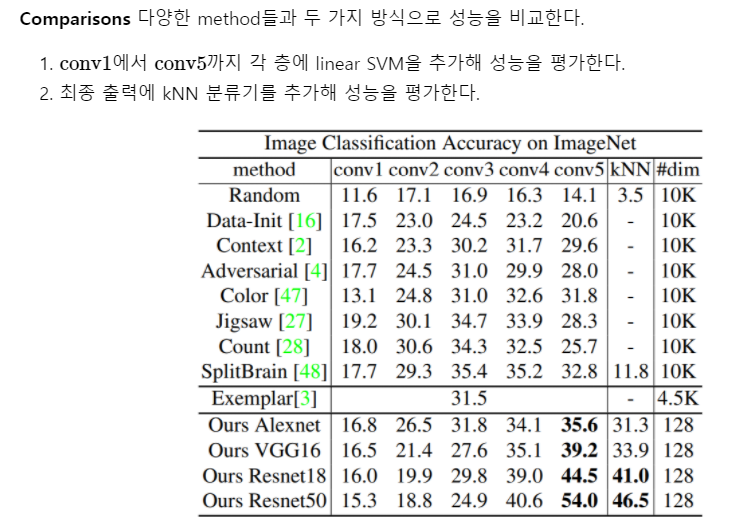
이전 논문의 경우 umsupervised learning을 통해 feature learning을 수행하면 SVM과 같은 linear classifier를 통해 classification을 수행했다.
그러나 SVM과 같은 linear classifier가 동작을 잘한다는 보장은 없다.
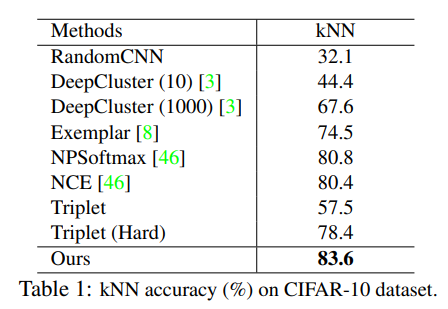
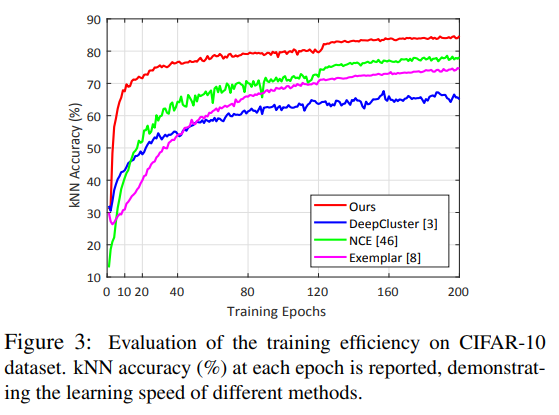
본 논문에서는 non-parametric한 방법인 kNN classification 방법을 사용한다.
이때, test time마다 거리 계산을 위해 training sample을 모두 embedding 시킬 수는 없기 때문에
memory bank를 활용하여 training sample을 embedding 시킨 값을 저장해놓는다.
(일반적인 classifier는 거리 계산을 위해 각 class의 대표값만을 저장해두는데, 그것이 weight이다.)
Non-parametric classifier
1) parametric classifier
일반적으로 사용하는 parametric classifier
2) Non-parametric Classifier
parametric과 다르게 instance 별로 진행한다.
이때 , v 벡터는 normalization을 적용하며, 아래와 같이 거리 기반으로 계산할 때, 유사한 class끼리 더 가깝게 embedding 되는 효과를 얻을 수 있다.
Noise-Contrastive Estimation
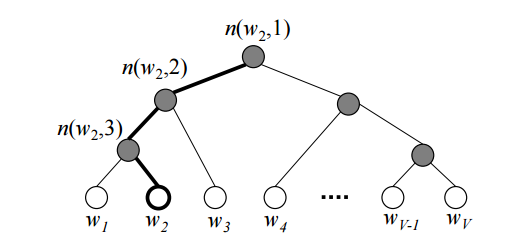
class수가 매우 많은 경우, softmax 계산이 어려워진다. 이와 같은 문제는 word embedding에서도 발생했었고 다음과 같이 해결 했다.
Hierarchical Softmax: 각 단어들을 leaves로 가지는 binary tree를 하나 만들고, 해당하는 단어의 확률을 계산할 때 root에서부터 해당 leaf로 가는 길을 따라 확률을 곱해 해당 단어가 나올 최종적인 확률을 계산한다.자세한 설명은 위 그림 클릭
Negative Sampling: 모든 단어들에 대해 Softmax를 수행하므로 계산량이 많아지는 것을 개선하기 위해 해당하는 단어와 그렇지 않은 일정 개수의 Negative Sample에 대해 Softmax를 수행한다.
1) data imbalanced learning은 high-quality representation learning 문제가 아닐 수 있다.
2) 가장 단순한 instance-balanced sampling을 통한 representation learning과 더불어 classifier만 adjusting하는 것이 가장 좋은 성능을 보일 수 있다.
Introduction
기존의 방법들은 representation과 classifirer를 따로 분리하지 않고 joint learning을 수행하였다.
그러나 이러한 방법들은 imbalanced learning에 대한 성능 향상이 어디서 오는 것인지 알 수 없다는 단점이 있다.
그래서 본 논문에서는 representation learning과 classifirer learning을 decoupled해서 분석한다.
representation learning을 비교하기 위해 다음과 같이 3가지 방법을 사용하고 비교해본다.
1) instance-based sampling
2) class-balanced sampling
3) mixture of them
classifier learning을 비교하기 위해 다음과 같이 3가지 방법을 사용하고 비교해본다.
1) re-training the parametric linear classifier in class-balancing manner
2) non-parametric nearest class mean classifier: which classifies the data based on their closest class-specific mean representations from the training set
3) normalizing the classifier weights, which adjusts the weight magnitude directly to be more balanced, adding a temperature to modulate the normalization procedure.
Method
- Sampling strategies
Sampling은 아래와 같이 class당 sampling될 확률을 정의함으로서, 수행되어진다.
이때, q는 sampling 전략을 나타내는 변수이며, 1, 0, 1/2 중 하나의 값을 가진다.
1) Instance-balanced sampling
q=1 일때 instance-balanced sampling을 수행하게 된다. class당 가지고 있는 sample의 수에 비례하여
sampling을 수행하게 된다.
2) Class-balanced sampling
q=0 일때, 이며, class당 sampling하는 확률을 모두 동일하게 가져가는 전략이다.
3) Square root sampling
q=1/2이며, sample의 수의 squre root에 비례하여 sampling하는 기법이다.
4) progressively-balanced sampling
본 방법은 Instance-balanced sampling과 Class-balanced sampling을 혼합한 방법이다.
초반 epoch에는 instance-balanced 기반으로 sampling을 진행하다가 일정 epoch이후에는 class-balanced 형태로
변형되는 sampling기법이다. 자세한 수식은 위와 같다.
- Loss re-weighting strategies
focal-loss, LDAM loss가 대표적으로 있다.
Classification for long-tailed recognition
1) Classifier Re-training (cRT)
representation learning 부분을 fixed하고 classifier만 class balanced 형식으로 다시 학습시키는 방법을 말한다.
2) Nearest Class Mean classifier (NCM)
먼저 각 train data의 class의 mean feature representation을 구한 다음, 이후 query vector의 L2 normalized feature를 활용해서 cosine similarity나 Euclidean distance를 이용해서 nearest neighbor search를 수행한다.
3) τ-normalized classifier
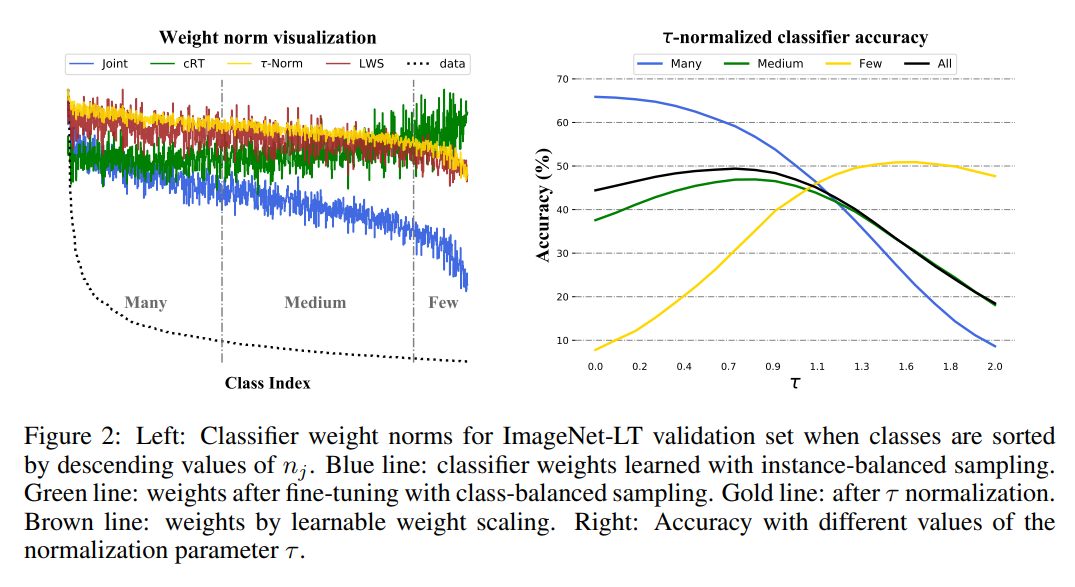
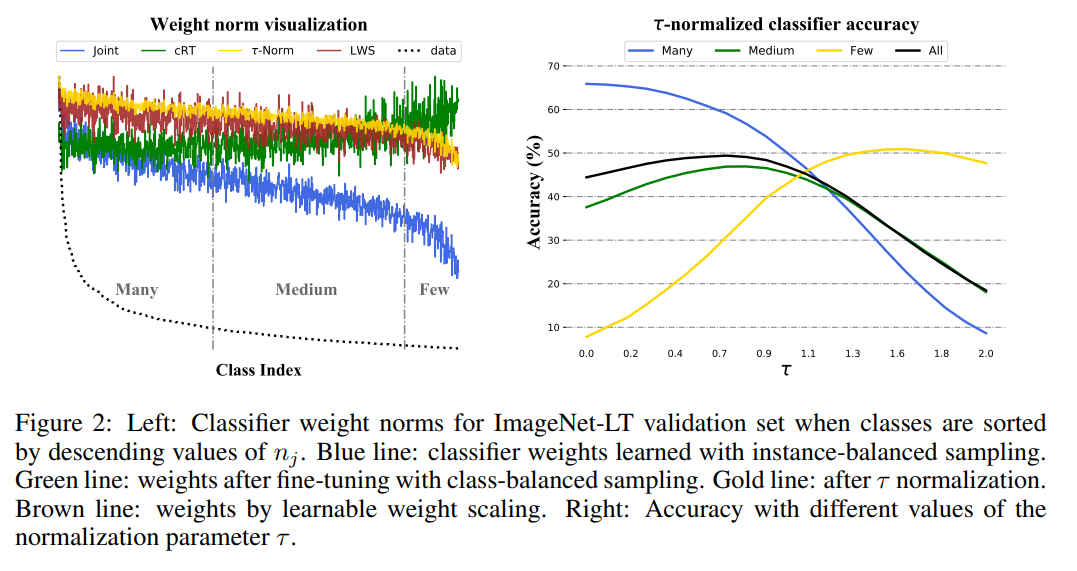
-instance-balanced sampling의 경우, weight값이 class sample 수에 비례하는 것을 확인할 수 있다.
(sample수가 많은 class의 경우 더 넓은 boundary를 가지게 되고, 이것이 weight값의 크기로 나타남)
-class-balanced sampline의 경우, class마다 sample수가 동일하기 때문에 weight의 값이 class마다 비슷하게 형성되는 것을 확인할 수 있다. (decision boundary가 유사해짐.)
- τ-normalization은 이 2가지 방법의 중간 정도의 방법이다. instance-balanced sampling의 weight에다가 normalization을 하여 'smoothing'한다.
이때 τ는 0~1 사이에서 결정된다.
- Learnable weight scaling (LWS)
scaling하는 정도는 학습을 통해서 얻는 방법을 의미.
Experiment
-Sampling strategies and decoupled learning
- joint training scheme
classifier와 representation learning이 함께 이루어지는 방식이다. 90 epoch 동안 cross-entropy loss 및 instance-balanced, Class-balanced, Square-root, Progressively-balanced.
- decoupled learning schemes
classifier만 다시 training 한다. cRT , NCM, τ-normalized classifier가 사용된다.
먼저 joint의 경우 더 나은 balanced 방법을 적용할 수록 성능이 향상되는 것을 확인할 수 있다.
(joint 부분만 보면서 세로로 분석하면 됨)
decoupled learning을 하는 경우, non-parametric 방법인 NCM을 적용한 경우라도 오히려 성능이 크게 향상되는 것을 볼 수 있다. parametric한 방법은 더욱 성능이 향상 된다. (가로축으로 성능 변화 살펴보면 됨)
여기서 중요한 발견 중 하나는 representation learning에 있어서 instance smapling이 가장 성능이 높다는 것이다.
이는 data-imbalanced issue는 high-quality representation을 배우는데 상관이 없음을 알려준다.
위 그림은 각 방법에 대한 decision boundary 형성을 그림으로 나타낸 것이다.
τ 가 0 인 경우는 normalization을 전혀하지 않은 경우이고, sample수에 비례해서 decision boundary도 정해지기 때문에 더 많은 sample을 가진 class가 더 넓은 decision boundary를 지님을 알 수 있다. τ가 1인 경우에는 normalization이 적용되기 때문에 좀 더 balanced된 boundary가 형성된다. Cosine 같은 경우 모두 같은 크기의 boundary가 형성된다. 마지막은 각 class마다 mean을 구하고 L2로 nearest neighbor 형태로 classifying을 할때, 나타나는 decision boundary를 나타낸 것이다.
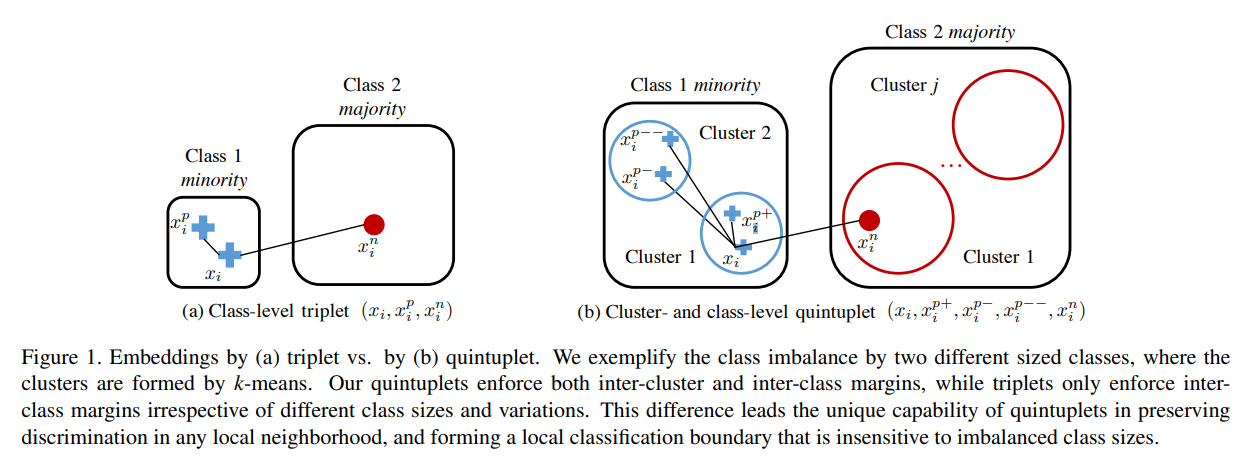
imbalanced problem의 근본적인 문제점은 minority class를 학습하기 위한 sample이 부족하다는 것인데, minority class에 대해서 4개의 anchor를 설정함으로 majority class에 비해 더 많은 학습 및 embedding을 형성하도록 하는 방법이다.
먼저 embedding 공간을 L2-norm이 1로 제한된 공간에 놔둔다.
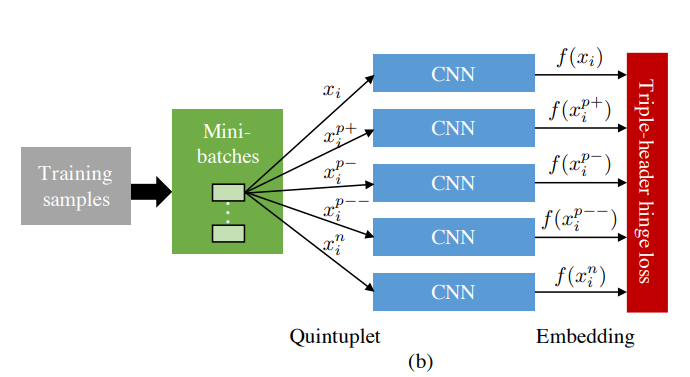
- Quintuplet Sampling
quintuplet은 다음과 같이 정의된다. (그림 참고)
이를 통해 다음과 같이 거리를 설정한다. (위 그림 참고)
이러한 quintuplet method는 2가지 메리트가 있다.
1) Triplet loss는 단순히 같은 class끼리는 당기고 다른 class는 떨어트리는 방식을 사용한다. 그러나 quintuplet은 class간과 class 내부의 instance level까지 같이 고려하기 때문에 더 rich한 feature를 추출할 수 있다는 장점이 있다.
2) under sampling 방법과 비교하면 information loss가 없고, over-sampling과 비교하면 주로 사용되는 artifitial noise가 없다는 장점이 있다. 실제 구현에서는 mini-batch에 minority class와 majority class 같은 숫자를 넣고 학습을 시킨다.
실제 구현에서 quintuplet을 선정하기 위해서는 이미 위 그림의 cluster들의 초기 형태가 형성되있어야 한다.
그래서 특정 데이터셋에서 pre-trained된 모델을 사용하여 feature를 추출하고 이를 통해 k-means clustering을 하여 cluster를 형성한다.
이러한 clustering을 좀 더 robust하게 하기 위해 5000 iteration마다 cluster 형성을 새롭게 업데이트 한다.
- Triple-Header Hinge Loss
위의 그림을 loss function형태로 구현 한 것이다. (잘 모르겠으면 margin loss 참고)
이와 같이 loss를 구현하면 실제로는 아래와 같이 embedding space가 구현된다.
learning하는 방식은 다음과 같다.
실제 학습할 때는 look-up table (dictionary 형태로 거리 저장한다는 의미인듯) 그리고 hardest한 학습은 피하기 위해서 실제 training set에서 50%만 random으로 sampling하여 사용한다.
요약하면 다음과 같다.
- Difference between "Quintuplet" Loss and Triplet Loss
Triplet Loss의 경우 class기반으로 같은 class 끼리는 뭉치게 만들고 다른 class sample끼리는 멀리 떨어지게 만들기 때문에, 실제 imbalanced data의 문제인 적은 sample 수를 가진 class의 적절한 boundary 혹은 margin을 표현하지 못할 수 있다. (실제로는 더 넓은 지역을 cover해야 하지만, few sample로는 넓은 지역을 다 cover 못할 수 있음)
이에 반해 Quintuplet의 경우, class 내부에 또 다른 cluster를 형성하며, 이는 class 내부에서 생기는 variance를 표현할 수 있다. 이를 통해서 좀 더 넓은 class의 margin 및 boundary를 형성할 수 있고. imbalance에서 생기는 적절한 boundary를 형성하는 문제에서 도움이 될 수 있다.
- Nearset Neighbor Imbalanced Classfication
본 논문에서는 Classification을 위해서 kNN Classification 방법을 사용한다.
기존 kNN과 차이점은 다음과 같다.
1) 기존 knn은 sample-wise로 classificaiton을 하였지만, 본 논문에서는 class마다 형성된 cluster-wise로 knn을 수행한다.
2) Classificaiton을 위해 다음과 같은 공식을 함께 이용한다.
요약하자면 assumtion 하는 class에 해당하는 가장 멀리있는 cluster와의 거리와 해당 class를 제외한 나머지 class의 cluster중에서 가장 가까운 거리를 계산해 차이를 구한다. 이때, 위 식의 값이 크다는 말은, 특정 class에 해당하는 cluster와를 max값을 취했는데도 작다. 즉, 가깝다는 의미이고, 특정 class를 제외한 class들과의 거리 중에서 가장 작은 값을 취했는데도 크다. 즉, 다른 class들과는 멀다는 의미이므로, 특정 class에 query가 가장 가깝다고 할 수 있다.
이러한 방식은 다음과 같은 장점이 있다.
1) imbalanced 환경에 더 강건하다:
기존 방법의 경우 가장 가까운 class의 개수를 통해서만 prediction하기 때문에 imbalanced 문제를 해결하기 힘드나 본논문에서 제시한 embedding 방법과 위의 classicification rule을 함께 적용하면, minority class에 대해서도 large margin을 가져갈 수 있기 때문에 강건한 결과를 낳는다.
2) cluster wise search를 수행하기 때문에 속도가 sample-wise에 비해 빠르다.
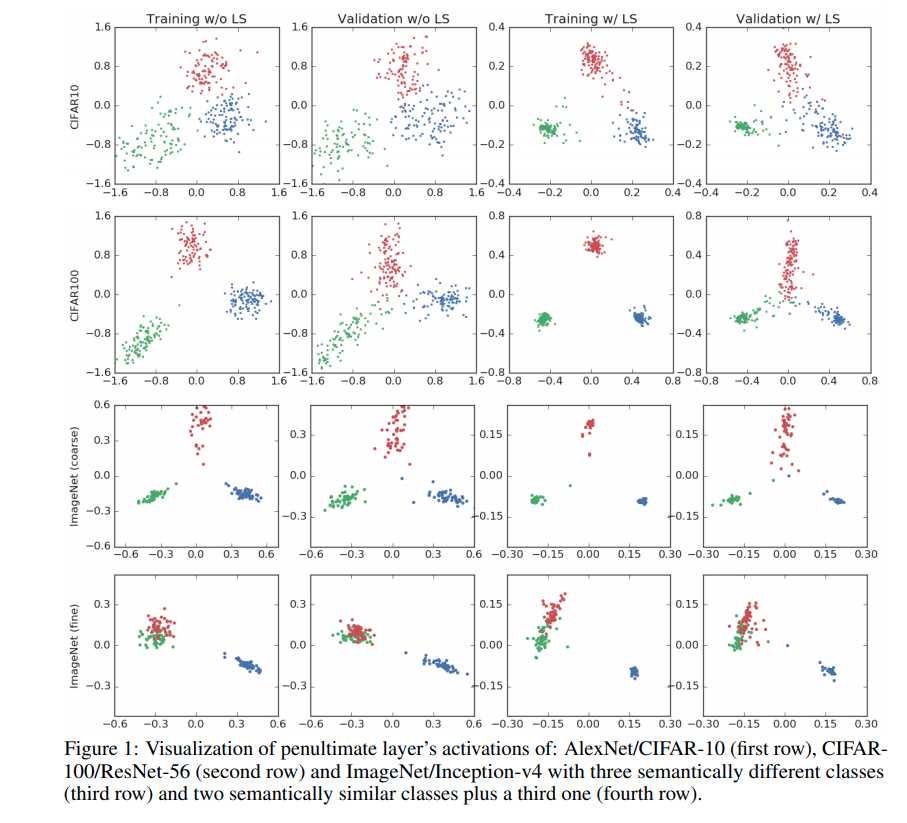
label smoothing을 적용하면 same class의 training example이 더 뭉치는 (tight) 형태로 representation이 형성되게 된다.
Penultimate layer representations
label smoothing을 하는 경우 uniform distribution에 fitting하는 항 때문에 input x가 incorrect class간의 같은 거리를 형성하도록 loss가 주어지게 되고, 결과적으로 embedding space에서 같은 class (intra class)끼리 좀 더 뭉치는 형태를 띄게 된다.
다음과 같이 uniform distribution를 이용해 regularization 하기도 하고,
knowledge distillation에서는 teacher model의 output을 이용해 regularization 한다.
Experimental Setting
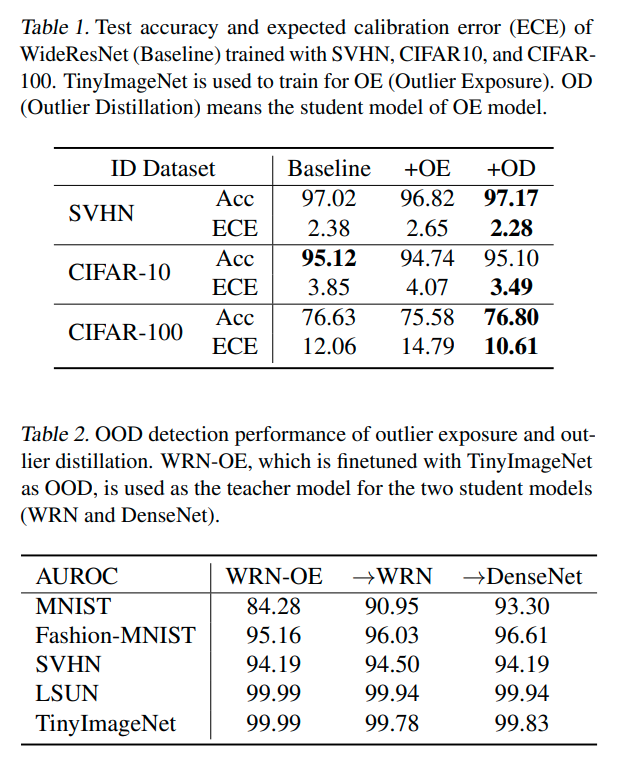
실험 세팅은 outlier exposure official code를 그대로 사용하였고, epoch 150만 학습했다는 점이 다른 점이다.
hyper-parameter setting은 다음 논문을 참고하였다. (when does label smoothing help? : NeurIPS 2019)
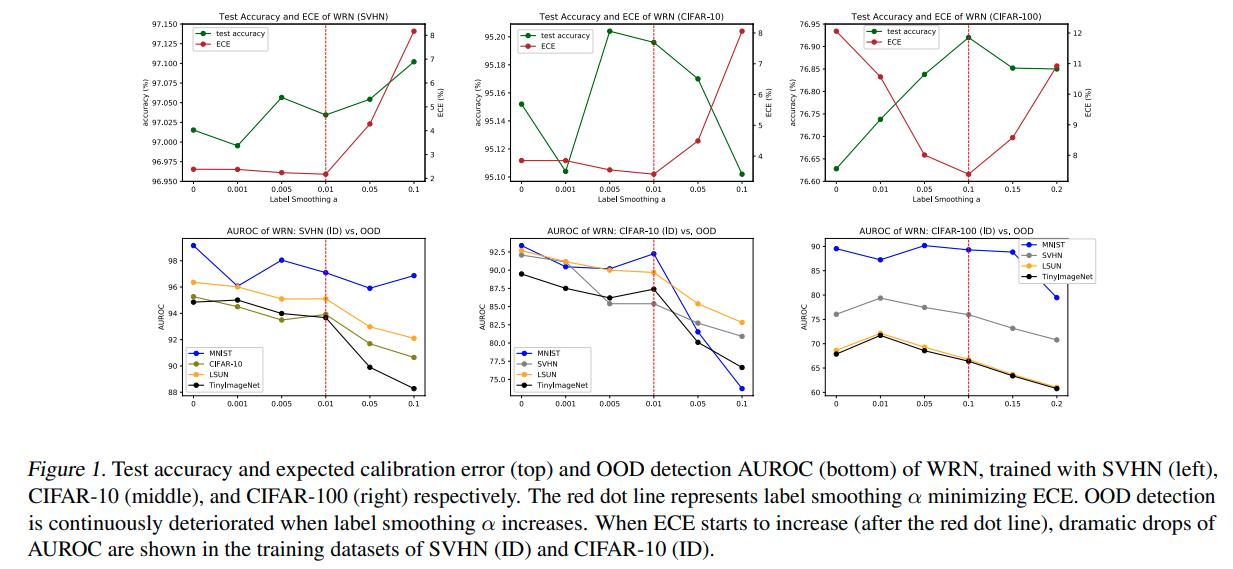
Label Smoothing and OOD Detection
- label smoothing에 대한 결과 test acc 를 증가시키고 ECE를 감소시키기는 하였으나 AUROC는 감소시키는 결과를 낳았다.
(*ECE: expected calibaration error , acc와 confidence의 차이를 말하는듯..)
- 그럼 왜 AUROC가 감소하는가? ID(In-distribution) sample에 대해서 uniform distribution regularization을 적용하기 때문에
OOD가 위치하는 embedding space의 중앙 부분에 ID sample이 위치하는 결과를 낳기 때문이다.
- 위의 실험 결과에서 보듯이 Regularization term 'a'가 커질수록 AUROC는 감소하는 경향을 보이게 된다.
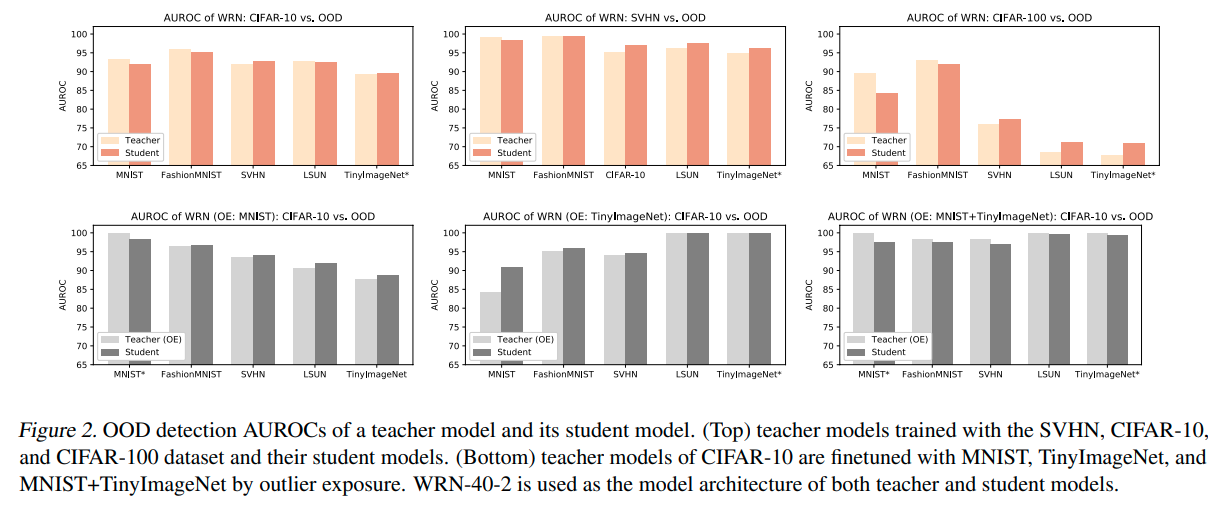
Knowledge Distillation and OOD Detection
- 위는 OE없이 distillation한 결과이다. teacher model과 비슷한 결과를 가져간다고 논문에서는 말하고 있다.
- 아래는 OE를 학습한 teacher model을 가지고 distilation한 결과이다. teacher model의 AUROC값을 그대로 학습하는 것을 확인가능하다.
-이 실험의 경우, OE에 의해 학습된 teacher model의 Knowledge를 이용해 soft labeling 학습을 하여 AUROC를 높혔지만, 반대로 생각해보면 어찌되었든, soft-label 학습을 통해 AUROC을 높일 수 있는 방법이 존재한다는 것을 의미한다.
(그러나 준비된 teacher-model없이 어떻게 soft-labeling을 생성할지는 아직 숙제이다.)
- 또한 이러한 distiling을 모델의 크기에 관계없이 적용이 가능한 것으로 확인되었다.
(큰 teacher model로 부터 작은 student model로 distiling해도 teacher AUROC 학습됨)
실험은 metric learning, classification, few-shot 3가지 분야에서 이루어졌다.
1) Metric learning
Metric learning은 유사한 이미지끼리는 가깝게 embedding하고, 다른 이미지끼리는 멀게 embedding되도록 obejective function을 정의하고 학습시키는 방식이다.
이러한 metric learning을 통해 학습된 embedding 모델은 image retrieval 방식으로 주로 평가된다.
본 논문에서는 CUB-200-2011, Cars 196, Stanford Online Products에서 평가되었다.
evaluation metric으로는, recall@K가 사용되었다. 먼저 test image들을 모두 embedding 시킨다.
그리고 각 test image들을 query로 사용하고 KNN 기법으로 query에 대한 이미지들을 retrieval한다.
(retrival할떄, query는 제외)
이때 query에 대해서 K개의 nearest neighbor중 같은 category의 image가 하나라도 포함되어 있으면
그 query에 대한 recall은 1이 된다. 즉 Recall@K는 모든 test set에 대해서 이 recall 값을 계산해서 평균값을 낸 것이다.
이때, loss는 Triplet loss를 사용하였다.
이때 최종 embedding vector에 대해서 l2 normalization을 수행한다.
일반적으로 deep metric learning에서 embedding space를 제한하기 위해 l2 normalization은 많이 사용된다.
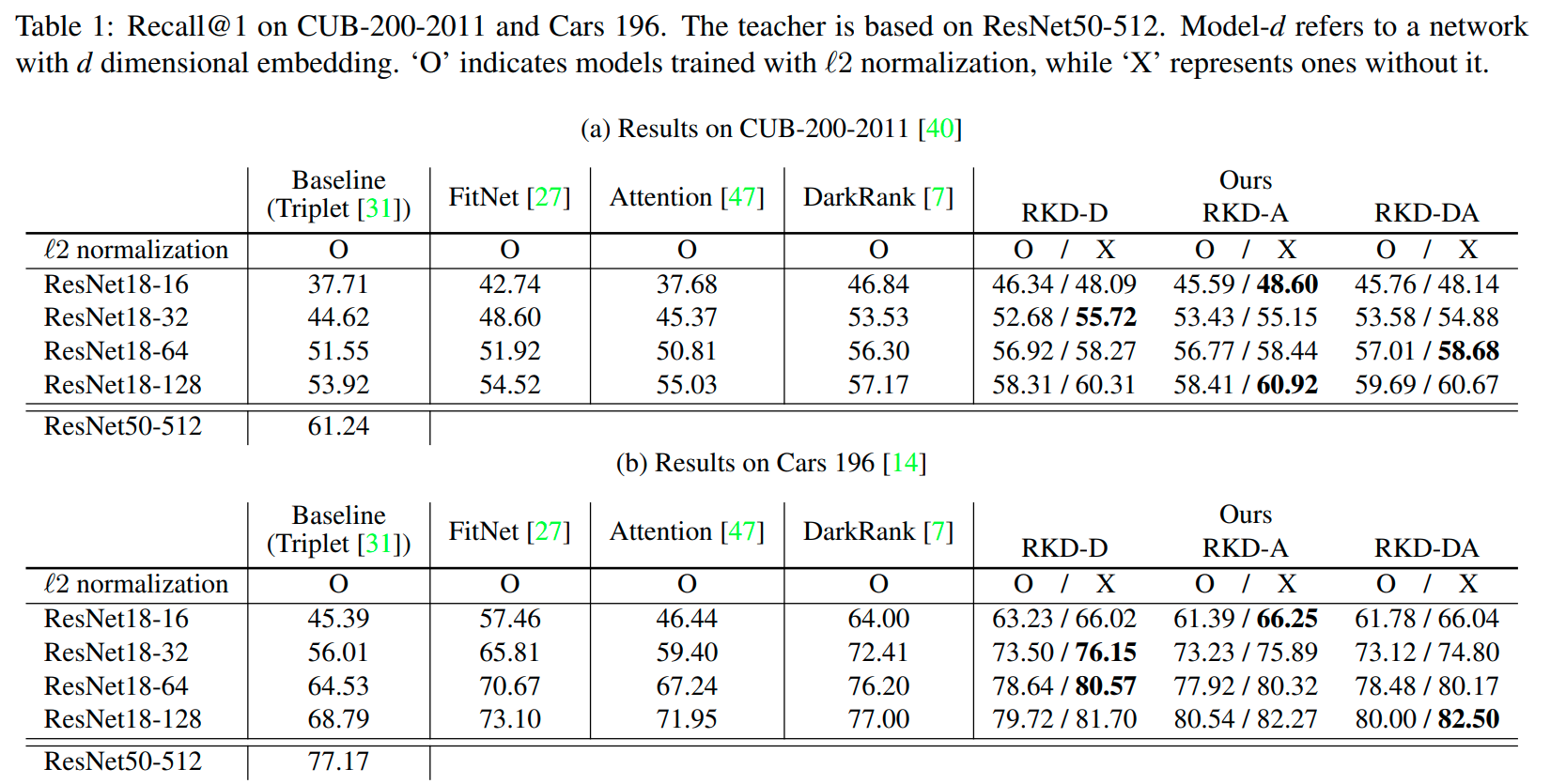
RKD는 teacher model과 student model의 final embedding ouput을 대상으로 적용된다.
이때, RKD의 경우 embedding space를 tripplet loss와 같이 normalization하지 않았으며,
RKD-DA의 경우 RKD-D는 1, RKD-A는 2의 비율로 loss를 적용하였다.
RKD를 사용할 때, 추가적인 task loss(ex triplet loss)는 사용하지 않았다. 즉, teacher model의 embedding 정보를 통해서만 student model은 학습이 되었으며, 기존의 gt label은 student 모델을 학습하는데 사용되지 않았다.
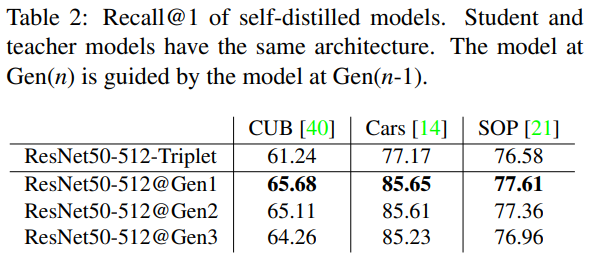
self-distillation도 효과 있었다.
이때 self-distilation은 teacher model과 student model이 동일한 backbone network를 사용하였음을 의미하며,
generation은 distillation을 통해 생성된 student model을 다시 teacher model로 사용하여 distiallation을 다시 수행했다는 것을 의미한다.
결과적으로 self-distillation을 한번만 했을때, 가장 효과가 좋았고, 그 이후로는 오히려 성능이 떨어지는 현상을 보였다.
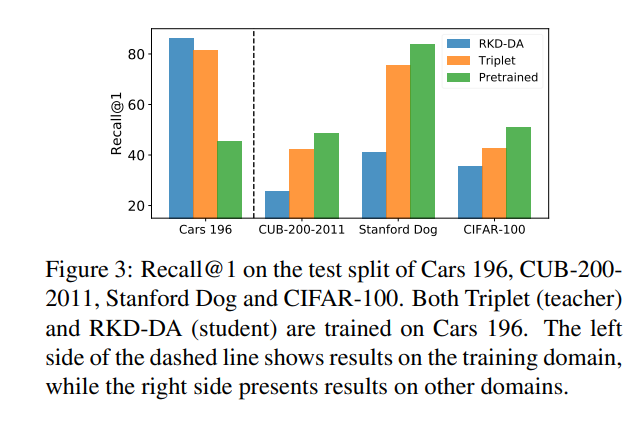
또한 RKD는 특정 dataset에 특화되어 학습되는 경향을 보였다. (adaptation)
Cars 196이나 CUB-200-2011은 fine-grained dataset으로서, domain의 특징에 잘 맞추어서 학습되는 것이 중요하다.
RKD가 이러한 adaptation이 잘되는 학습방법임을 증명하기 위해서 Car196에 학습시킨 모델을 다른 dataset에 대해서 test해 보았다.
결과적으로 RKD-DA는 Cars196에 대한 성능이 좋은 반면에 다른 dataset에 대한 generalization 성능은 떨어지는 것을 확인할 수 있었다. 즉, 해당 데이터셋에 대한 discriminative한 feature를 더 잘 추출하는 경향이 있음을 알 수 있다. (왜?)
2) Image classification
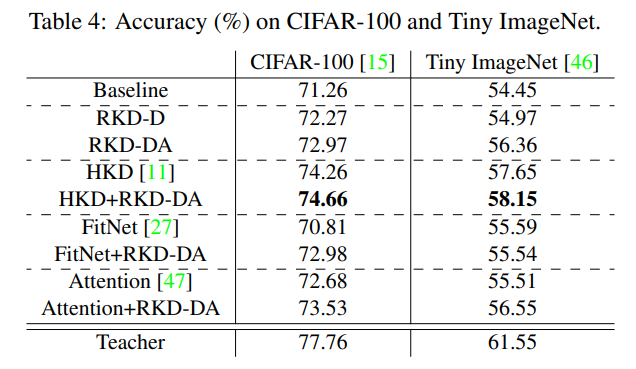
classification에서는 기존에 사용되던 KD들과 성능을 비교하였다.
RKD 단독으로 사용했을 때는 오히려 HKD(Hinton's KD)가 더 높았으나, RKD와 다른 기존의 KD를 조합했을때, 모두 성능이 더 향상되었으며, 또한, 가장 높은 성능을 보였다.