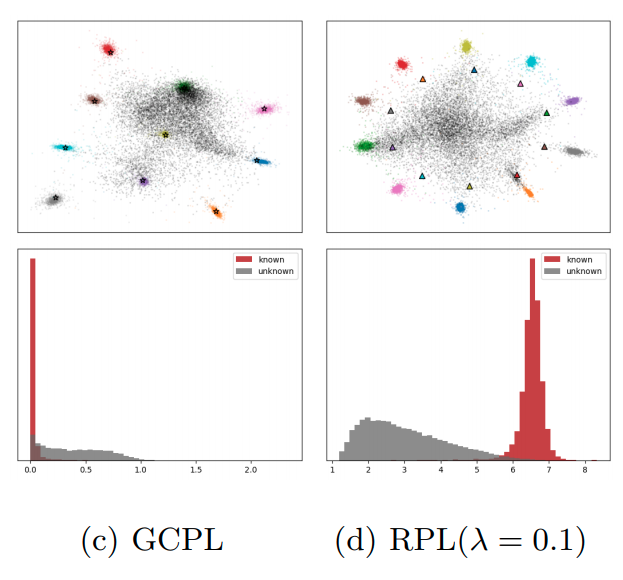
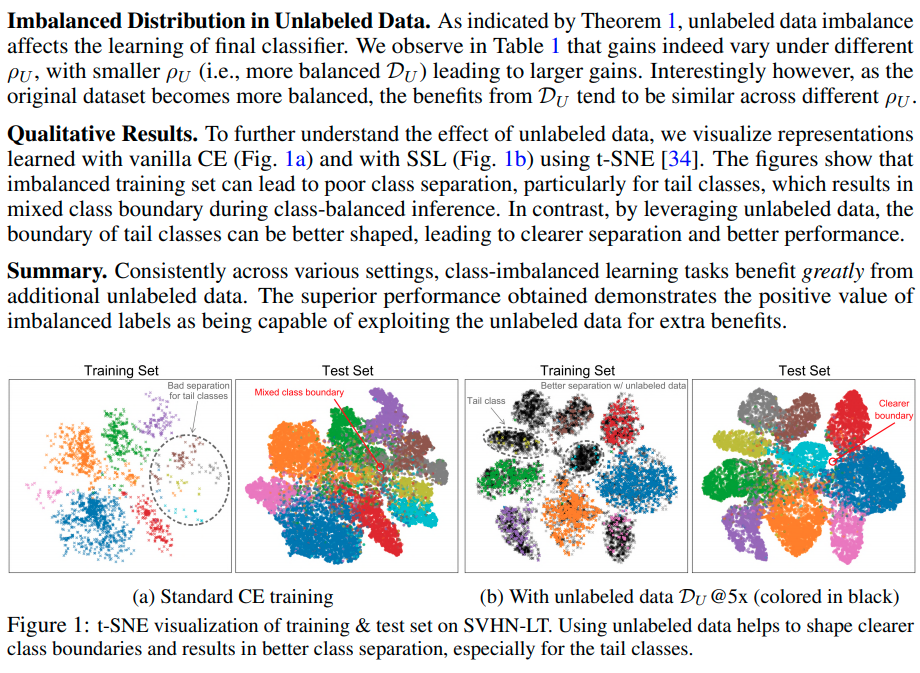
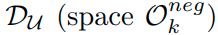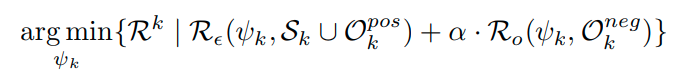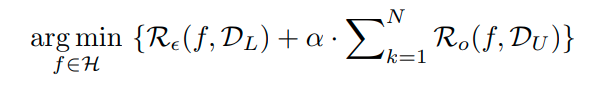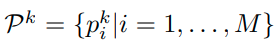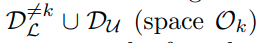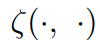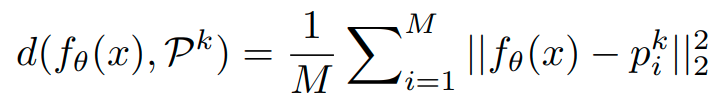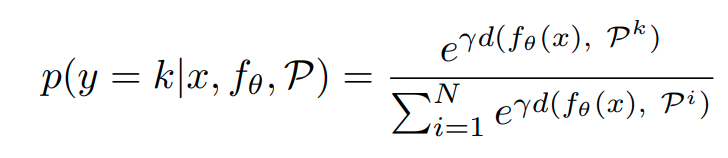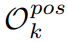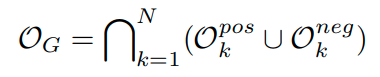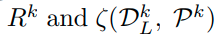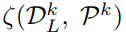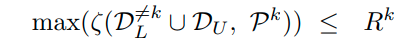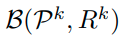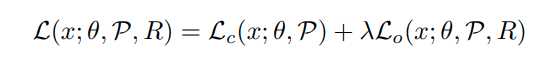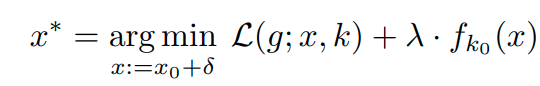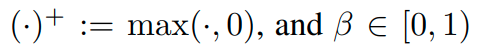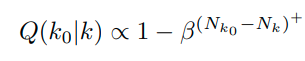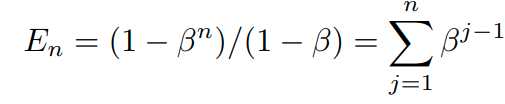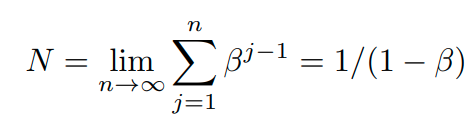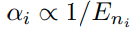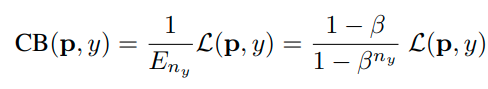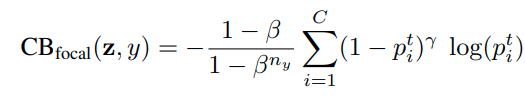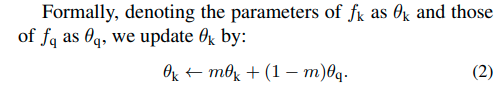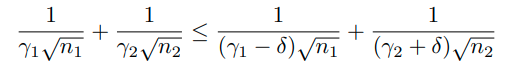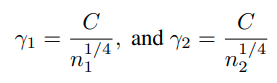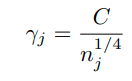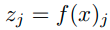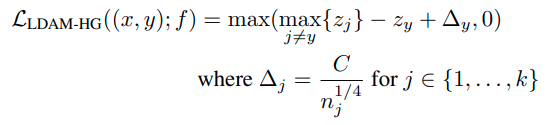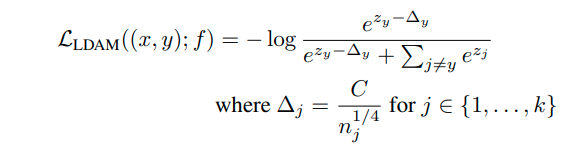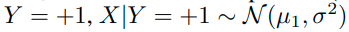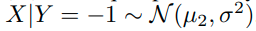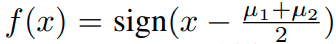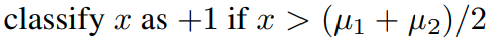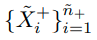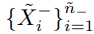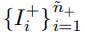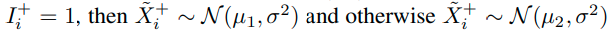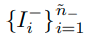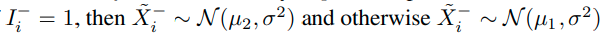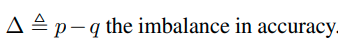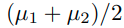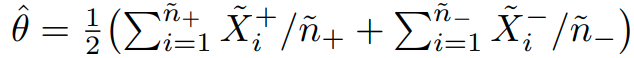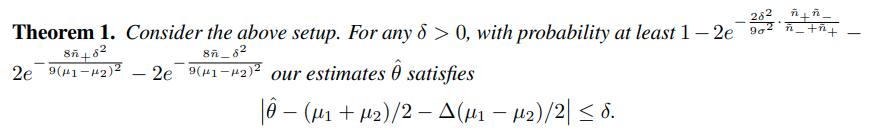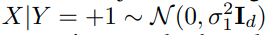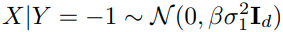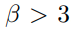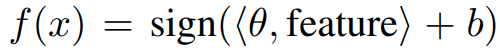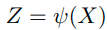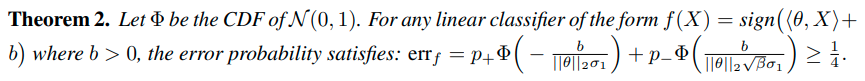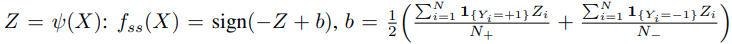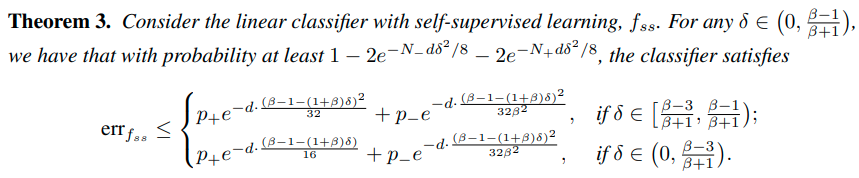Paper
Self-supervised Label Augmentation via Input Transformations
Self-supervised learning, which learns by constructing artificial labels given only the input signals, has recently gained considerable attention for learning representations with unlabeled datasets, i.e., learning without any human-annotated supervision.
arxiv.org
Code
hankook/SLA
Self-supervised Label Augmentation via Input Transformations (ICML 2020) - hankook/SLA
github.com
Introduction
그동안의 self-supervised task를 이용한 방법은 multi-task learning의 형태가 많았다.
(Multi task learning은 아래 그림 참고)

그러나 multi task learning 방식은 단순히 supervised 방식을 사용했을 때 보다 acc gain은 없다.
그렇다면 어떻게 self-supervision을 fully supervised classfication task에 적용하는 것이 가장 좋은 방법일까?
Contribution
먼저 multi task learning의 경우 primary network에 대해서 self-supervision task (transformation)에 대해서 invariant하게 만든다. 예를들어 Rotnet의 경우 rotation에 대해 invariant하게 만들어주는 방식이다.
그러나 이러한 invariance는 오히려 task에 대한 난이도 및 복잡도를 증가시킬 수 있다.
예를들어 {6 vs 9} 와 {bird vs bat} 같은 경우 회전때문에 오히여 두 클래스가 더 헷갈릴수도 있기 때문이다.
그리고 이러한 이유 때문에 오히려 multi-task learning이 성능이 더 저하되는 경우가 생긴다.
(아래 그림 baseline과 MT(Multi-Task) accuracy 비교)
이러한 문제를 해결하기 위해서, 저자들은 기존의 label과 self-supervision label을 조합한 joint distribution을 제안한다.
예를들어 cifar10 dataset과 Rotnet을 조합하는 경우 10 label * 4label (0, 90, 180, 270) 총 40 label이다.
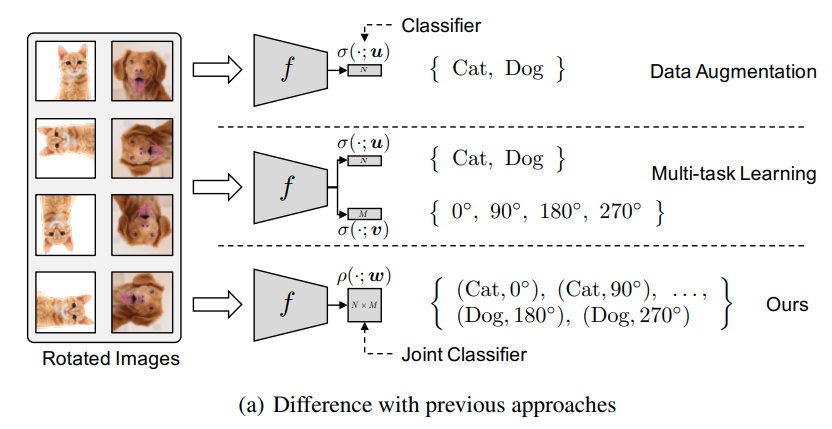
이렇게 하면 multi task learning의 경우 class에 대한 label 없이 Rotation에 해당하는 label을 맞추어야 하기 때문에 오히려 classificaition 성능이 떨어지는 상황이 발생하나, joint의 경우 각 input으로 들어오는 image가 어떤 class에 대한 정보를 rotation과 함께 부여하기 때문에 이러한 문제가 해결할 수 있다.
또한 아래 그림과 같이 특정 class에 대한 self-supervision prediction에 대한 결과들을 aggregation하여 앙상블 효과 또한 얻을 수 있다.

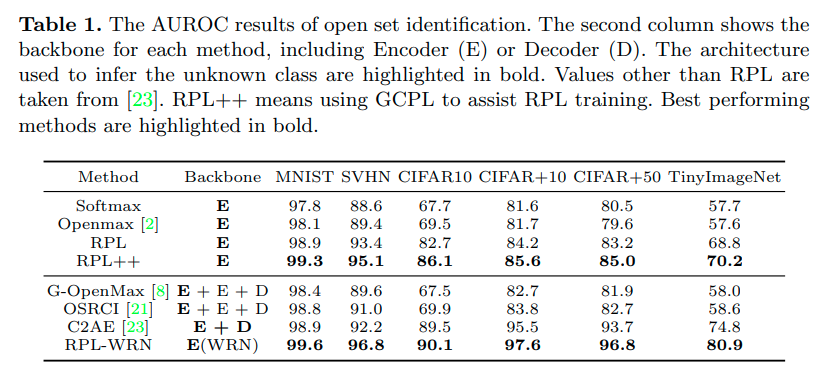
본 논문에서는 self_supervision task로서 Rotation과 Color Permutation 방법을 사용했으며, fully-supervised, few-shot, imbalanced dataset에서 성능향상을 볼 수 있었다.

Self-supervised Label Augmentation
* notation
input :

label : (N은 class의 수)
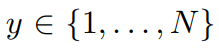
cross entropy loss function:
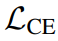
softmax classifier :
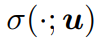
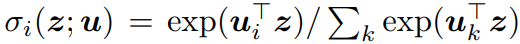
embedding vector of x :
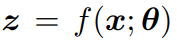
augmented sample using transformation t
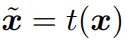
the embedding of the augmetnted sample x:
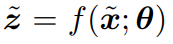
Aggregated inference
label을 joint하여 learning한 이후에 inference의 경우는 다음과 같이 한다.
class에 해당하는 self-supervision transformation의 logit을 모두 더한다.
그렇게 하면 class별 logit이 새롭게 산출되고 이를 softmax를 이용해서 prediction한다.
이러한 방식은 앙상블 방식으로 해석할 수 있는데,
실제로 independent한 여러개의 모델을 앙상블 한 것 보다 더 높은 성능이 나왔다.
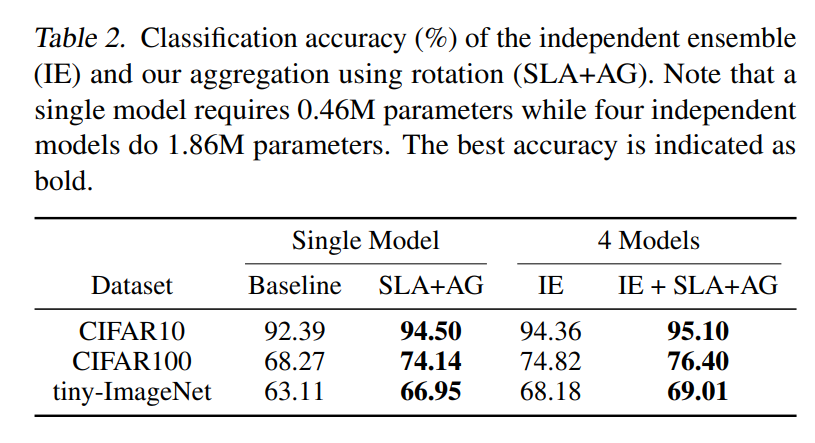
Self-distillation from aggregation
aggrregation이 성능향상에 큰 도움을 주기는 하지만, inference과정에서 기존의 label보다 훨씬 많은 label에 대한
summation 계산과정이 있기 때문에, computation cost가 존재한다.
이러한 inference과정에서 computational cost를 줄이기 위해서 본 논문에서는 self-distillation방법을 사용한다.
그래서 aggregated된 knowledge
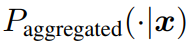
를 다른 classifier에 distillation한다.(그림참고)
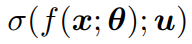
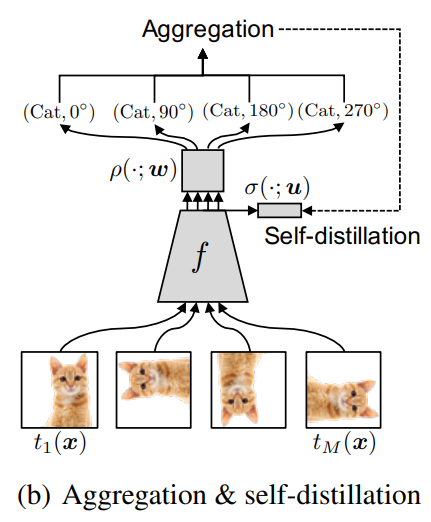
즉 feature extractor에 n*m (label 개수 10*4)의 classifier와 n(label 개수 10) classifier 2개를 놓고, n*m classifier는 label을 통해 학습시키고 n classifier의 경우, distilation을 통해 학습시킨다.
그리고 inference 단계에서는 self-distilation을 통해 학습된 classifier를 이용해 inference한다.
최종적인 loss function은 다음과 같다.
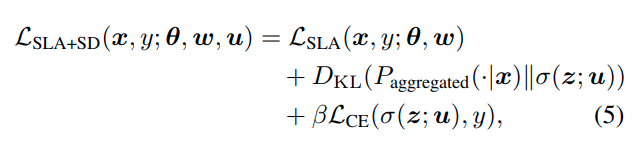
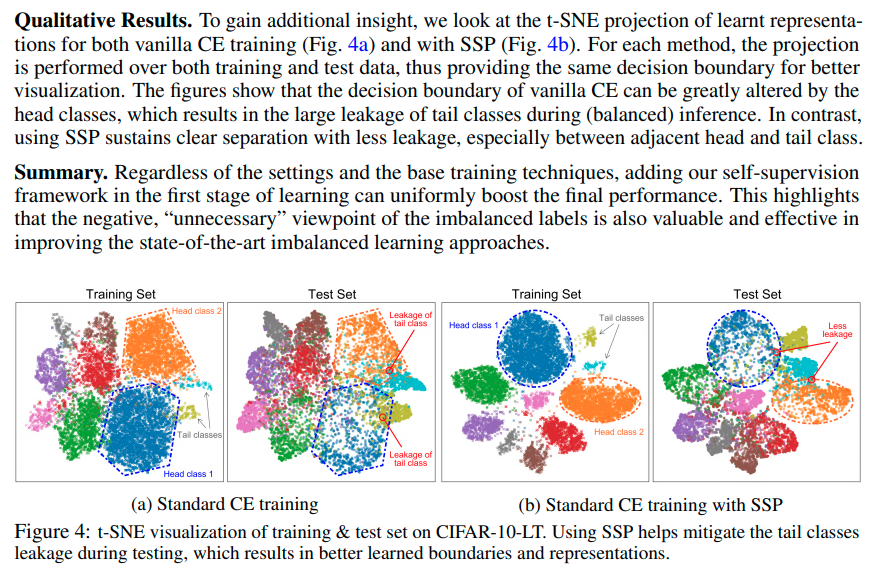
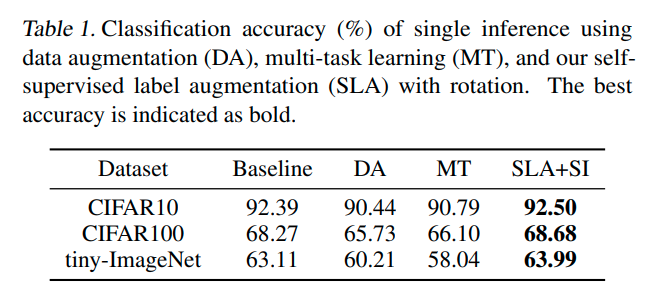
Comparison with DA and MT
본 논문에서는 data-augmentation과 Self-supervised Multi-task learning이 유사한 성격을 지닌다고 주장하고 있다.
또한 rotation 기반으로 생각했을 때, unnecessary한 invariant 속성을 학습하기 때문에 오히려 성능이 떨어진다고 주장한다.
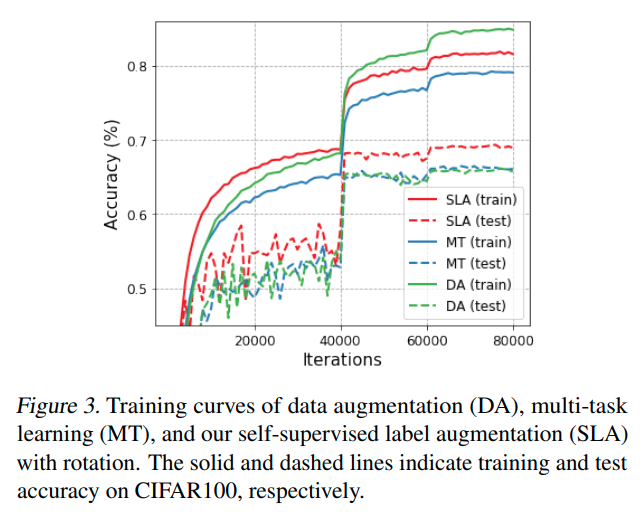
이때, test에 대해서 DA와 MT가 낮은 것은 앞선 unnecessary한 부분을 invariant하게 만들기 때문이다.
MT가 train 및 test 모두 성능이 안좋은 이유는 optimization 자체가 hard하기 때문이라고 말하고 있다.
위의 그래프에 대한 성능은 아래와 같다.
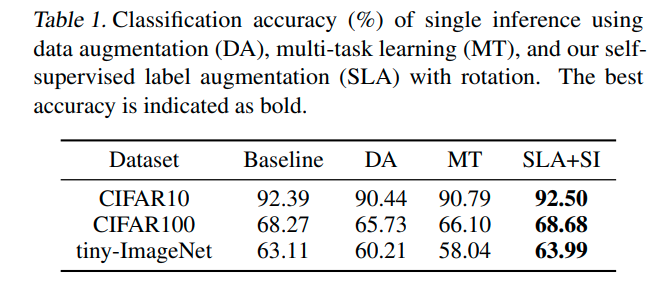
이때 DA가 Baseline보다도 성능이 낮은데, 둘의 차이는 rotation based augmentation이 있냐 없냐의 차이이다.
내 생각엔 Baseline에 다른 augmentation이 분명 포함되어 있을거라고 생각한다.
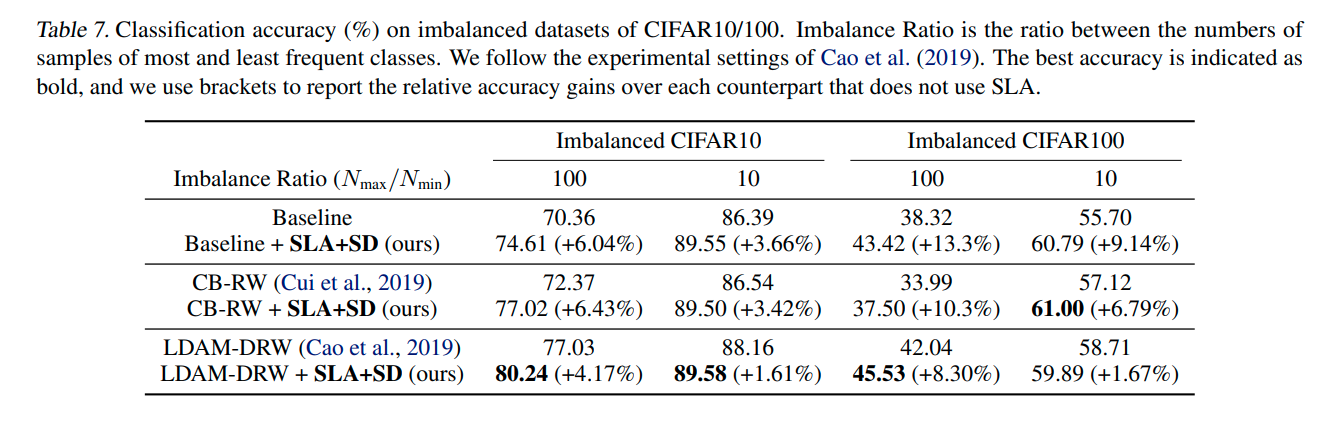
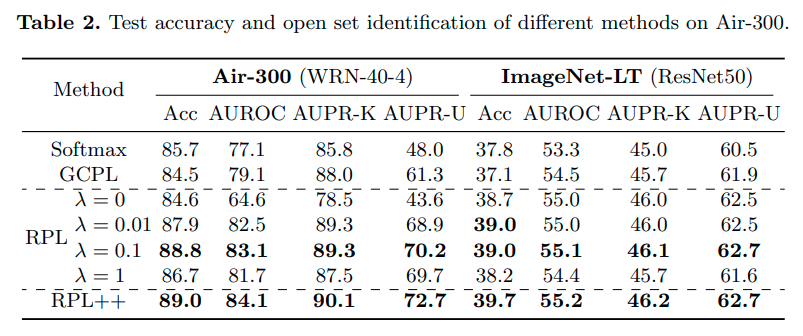
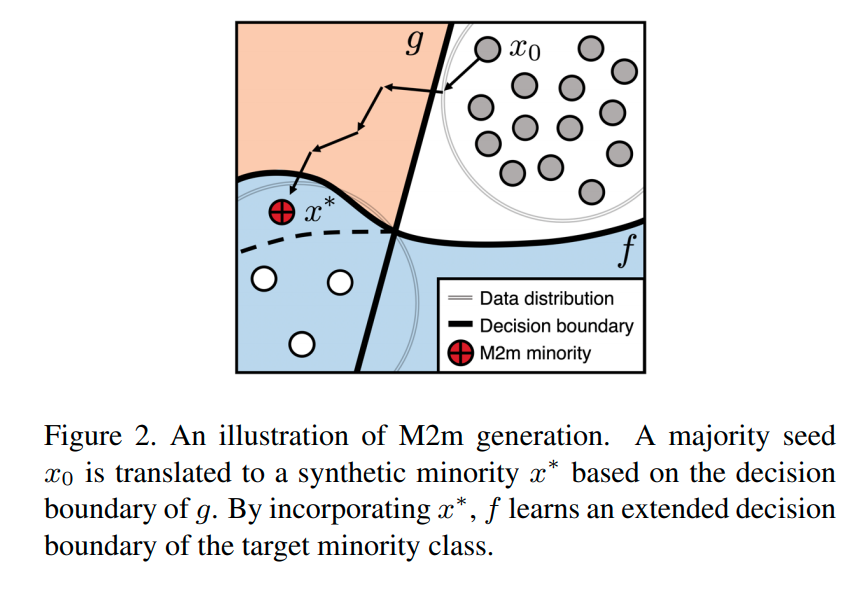
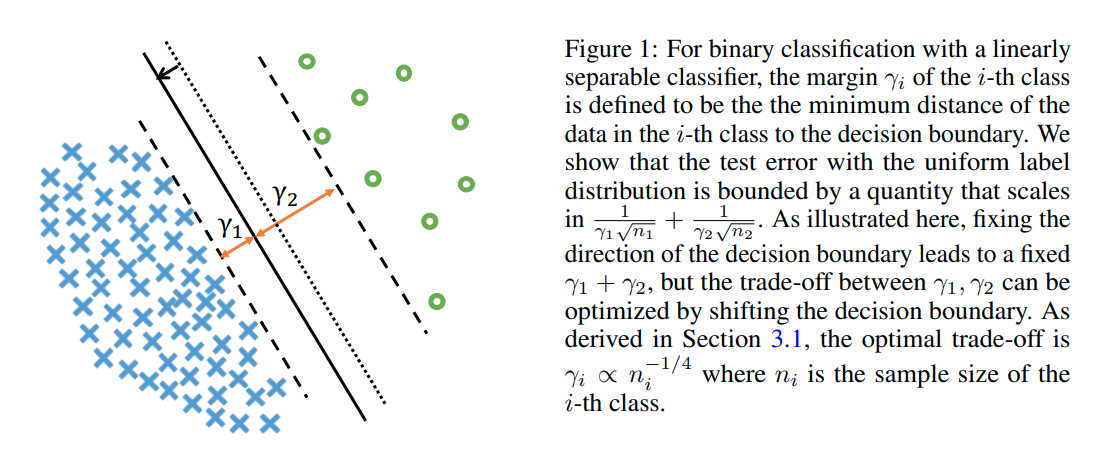
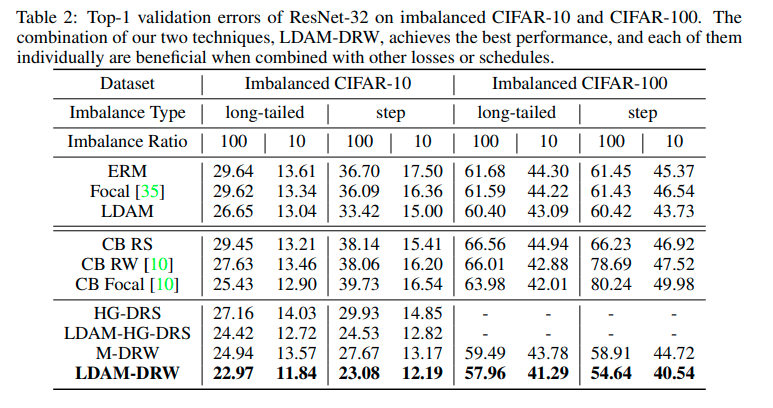
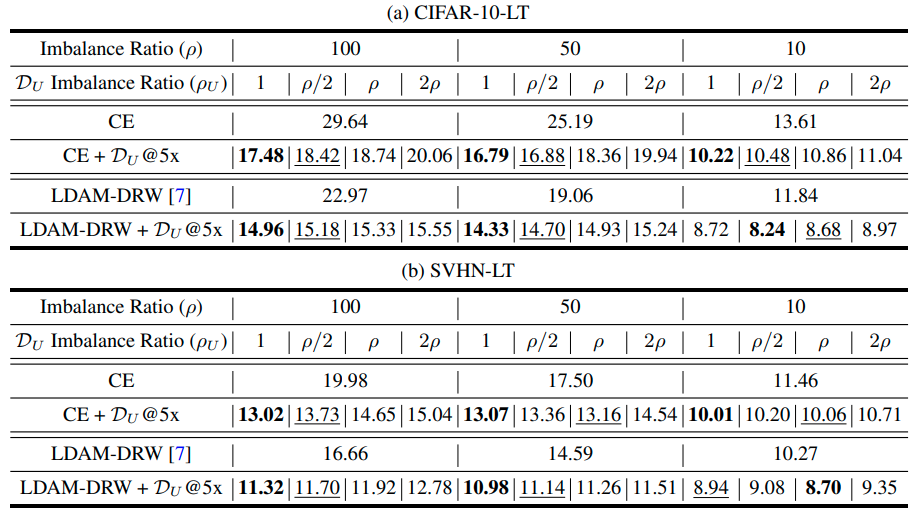
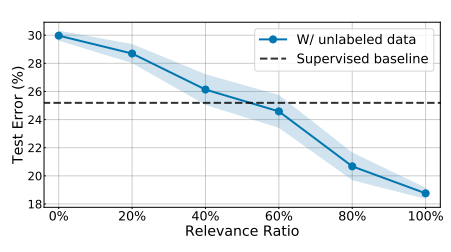
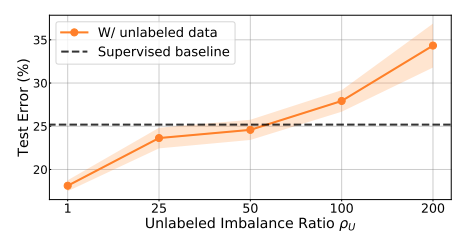
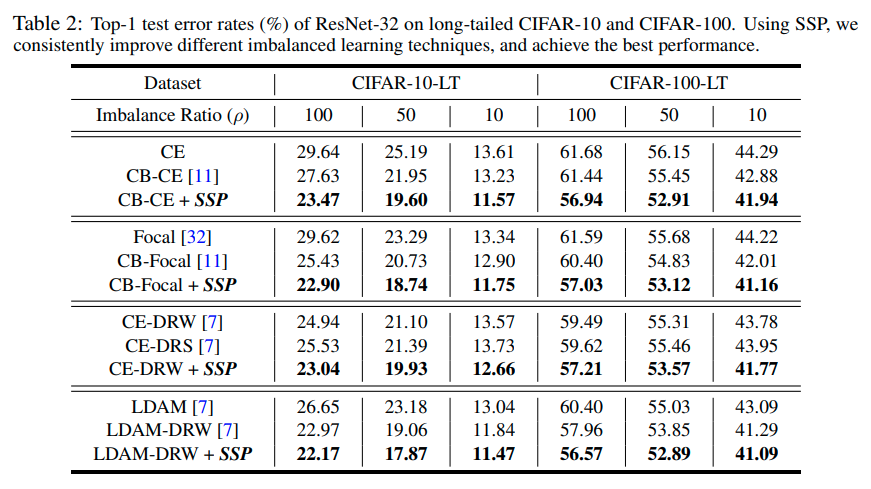
Imbalanced classification
Imbalanced classification에도 큰 성능향상을 보임 (왜?)